 |
3. DISCRETE-EVENT SIMULATION |
| INTRODUCTION |
We saw in the previous chapter an overview of the possibilities offered by general object-oriented programming languages. However, the OO approach has been first introduced with SIMULA, for the purpose of simulation. So, in this chapter, we will present the concepts of modeling and simulation to finally introduce discrete-event simulation, which is a specific kind of simulation and the one implemented by VSE. All along this chapter, we will see some aspects directly comparable to the OO approach. That explains why such an approach has been imagined. Then, we will discuss the necessity and the actual possibility of a visual simulation. Finally, we list the different software available in the market, in order to situate VSE among these products.
| MODELING |
| System |
The purpose of modeling and simulation is the study of a "system". Numerous definitions of a system are given. We just say that a system is an "assemblage of entities joined in some regular interaction of interdependence" ([Gordon 78]) and complete this definition by adding that they act with a common aim.
We introduce now some terms commonly used for the description of a system ([Gordon 78], [Law 82]). The term "entity" is used to denote an object of interest in the system. The properties of an entity are called "attributes" and the processes that cause changes in the system are called "activities". Finally, the term "state" of a system designates entities, attributes and activities in the model at a given time. The dynamism of a system corresponds to a change in the state of the system. The comparison with the OO approach is obvious, but these terms must be considered in a more general context. OO is just one particular approach to represent a system. The notion of "system environment" must be introduced to designate the outside of a system. The first difficulty that occurs when modeling a system is to determine the boundaries between the system and its environment. The decision depends on the purpose of the study.
Changes in a system can occur by different ways. First, they can occur smoothly, like a car accelerating for instance. On the other hand, they can occur discontinuously, at specific points in time, like lights that are switched on and off suddenly. A few systems are fully continuous or discrete. However, one type of change predominates and allows a classification of the systems as being "continuous" to refer to the first case of change or "discrete" for the second case ([Gordon 78]). Of course, this classification depends on the point of view of the analyst and the aim of the study.
| System Modeling |
There are different ways to conduct the study of a system. The first is to experiment with the system itself. However, it is rarely possible. A reason for that can be that it is technically impossible. For instance, the placement of sensors in the system can perturb it too much. Then, the cost of such an experiment can be very expensive. And finally, the other reason can be that the system does not exist or is partially incomplete. In this case, the creation of prototypes is possible, but generally expensive. Finally, a way to study a system is to make a model of it. It is a substitute and a simplification of the system, which must be cheaper than modifications on the system or the creation of it.
Of course, a model of a system is not unique, because it directly depends on the aim of the study. In fact, a model is based on information gathered for the purpose and on assumptions made to simplify the view of the system ([Gordon 78]). Moreover there are different natures of models we present now.
| Types of Model |
Figure 14 presents a classification of the different kinds of model ([Gordon 78]). The models are first separated in "physical" and "mathematical" models. Physical models are concrete systems based on some analogy with the original system. For instance, a system and a scale model of it have similar properties in some contexts. Another example is the well-known analogy between the oscillations of a spring and the oscillations in an RLC electrical circuit ([Gordon 78]). On the other hand, mathematical models are abstractions using symbolic notations. By notations we mean mathematical equations as well as any other form of formalism, usually provided by an analysis or a design method.
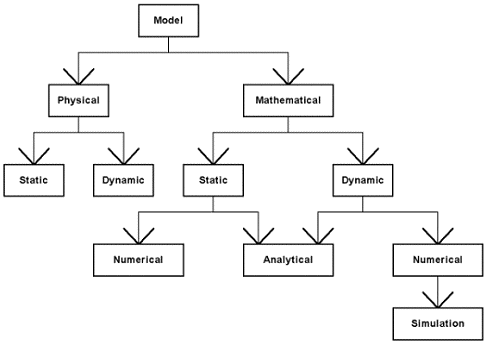 |
Another distinction is made between "static" and "dynamic" models. In a static model, the notion of time is not considered. The interest is the state of the system when it reaches an equilibrium, whereas dynamic models explicitly introduce the time and the interest is the evolution of the state of the system. For instance, the scale model of a molecule illustrates the notion of static physical model whereas the RLC electrical model of a spring represents a dynamic physical model. In a same way, equations representing a system can introduce the time variable or not. This distinguishes respectively the dynamic and the static mathematical models. Then, a third distinction is made for the mathematical models. It depends on the way they are solved. Two categories of method are considered: "analytical" and "numerical". Analytical methods mean the use of a deductive reasoning of mathematical theory to solve a set of equations and provide an exact solution, whereas numerical methods are based on computational procedures to approach the solutions. Simulation models are considered as numerical models.
Another distinction can be made between "deterministic" and "stochastic" systems, which induces two kinds of model. The first kind means that the behavior of a system is perfectly well known, whereas the second category means that there is random (or extremely complex) phenomena in the system. However, in the case of simulation models, the introduction of a random aspect complicates the interpretation of the results but does not change the basic technique by which the simulation is applied ([Gordon 78]). That is why the distinction is not made explicitly in the figure. For the modeling, this characteristic does not induce fundamental changes.
| Concepts Used in Modeling |
To build a mathematical model, Gordon underlines that it is impossible to provide rules, but he gives some guiding principles shown below. Two of them have been described previously in the presentation of the OO approach, it is the "block-building", we called it modularity, and the aggregation. The other principles help to identify the details to include in the model. Here are the three principles (excluding the aggregation) found in [Gordon 78].
Block-building: A system can be decomposed in blocks considered themselves as systems. Usually, they are called "subsystems". That allows different levels of abstraction and the possibility of analyzing separately each subsystem. In fact, from a subsystem, the other subsystems are its environment.
Relevance: Only relevant details of a system must be modeled. Irrelevant details are harmless for the model but complicate it. The choice of the details to introduce in the model directly depends on the aim of the study and the impact of such details in the modeling. If the error introduced by not including a detail is acceptable, i.e. modifies insignificantly the results, this detail can be forgotten.
Accuracy: The accuracy of the information introduced in the model must be considered and a good accuracy must be provided for the key information of the model. A good modeling with inaccurate information can give results totally away from the reality. Two difficulties are induced: what are the key information of the system and how to verify the results of a simulation ?
| SIMULATION |
| What is it ? |
As we saw it before, simulation represents a way to solve mathematical models. Simulation means imitating the operation of the real system through a model ([Banks 96]). That imitation can be done manually, or by a computer. In the last case, that means the model must be translated in a formalism understandable by a computer. That is why Michel Gourgand proposed the concepts of "knowledge" and "action" models ([Hill 96]). The knowledge model is the mathematical model first defined. Then the choice of the method for solving the model is done. Hence, the model is adapted to the technique of resolution chosen. This translation is the action model. In the case of a computer-assisted simulation, the action model, also called "simulation" model, corresponds to the program written in a specific computer language. The simulation is the fact of running the program. During it, observations can be made and data collected. Results are then analyzed and choices in the real system are made.
| When and Why Use the Simulation ? |
When a knowledge model is defined, a method to solve it must be chosen. Sometimes, analytical methods can be used, but unfortunately, the problems solved by these techniques are limited. Analytical methods imply a lot of simplification from the original system, which limits the complexity of the systems studied. Other times, the analytical resolution is virtually possible but request too much computation time. For these reasons, simulation appears often to be the best solution to solve problems concerning very complex systems. Simulation presents a lot of advantages ([Banks 96]) compared to other methods.
But important critiques are usually made concerning the difficulty of learning the modeling techniques and analyzing the results. Moreover, it stills time consuming and expensive. However, as we will see further, vendors of simulation software develop packages providing generic solutions for a category of system, output analysis capabilities and exploit the graphic possibilities of computers to make the learning and the use of the software easier. Finally, the advances in hardware allow simulation to be executed faster every day.
[Rothenberg 89] presents some limitation in using simulation to solve problems. He explains that simulation answers questions like "What if X ?" but simulation usually can not answer directly to questions like "Why did X happen ?", "When does X happen ?", "How can X be done ?", "Can ever / never X happen ?" or optimization questions such as "What is the highest value of X ?".
However, in these cases, simulation may be used as part of a whole solver. For instance (see Figure 15), in the case of the optimization of a criterion, it exists algorithms and heuristics to progressively find the best solution or to approach it. However, these algorithms may need estimations of the performances of the system for a given value of the criterion in order to evaluate the quality of the value proposed. And sometimes, the only way to do it is a simulation. In the coupling of an optimization method with a simulation model, the algorithm or the heuristic is the main procedure that runs a simulation when it is needed.
Figure 15: Coupling Algorithm / Heuristic and Simulation Model.
 |
| Continuous and Discrete Simulation |
We saw before that systems are classified as discrete or continuous. In a same way, simulation models can be considered continuous, discrete or both ([Banks 96]). There is no direct relationship between the nature of a system and the nature of its model. Because of the fact that a system is not fully discrete or continuous, it is possible to find a point of view for each kind of model. In the same way, a model can have both particularities. Discrete events in the model can influence a continuous evolution of the model, and continuous variables of the model can reach specific conditions that make a specific event occur. The reason this distinction does not appear in Figure 14 is that it is important only when the technique of resolution is chosen ([Gordon 78]). In the case of simulation, it influences only the way the model will be implemented in the computer. In fact, discrete and continuous simulations differ totally according to this point of view.
| Steps of a Simulation Study |
There is no formal procedure to conduct a simulation study, but [Gordon 78], [Law 82] and [Banks 96] agree to say that general steps are followed. Figure 16 ([Banks 96]) presents the different steps of a simulation study, showing that usually they are not followed sequentially one time but decisions, verifications are made between these stages that can induce callbacks to previous steps. We discuss here briefly each stage.
Figure 16: Steps of a Simulation Study.
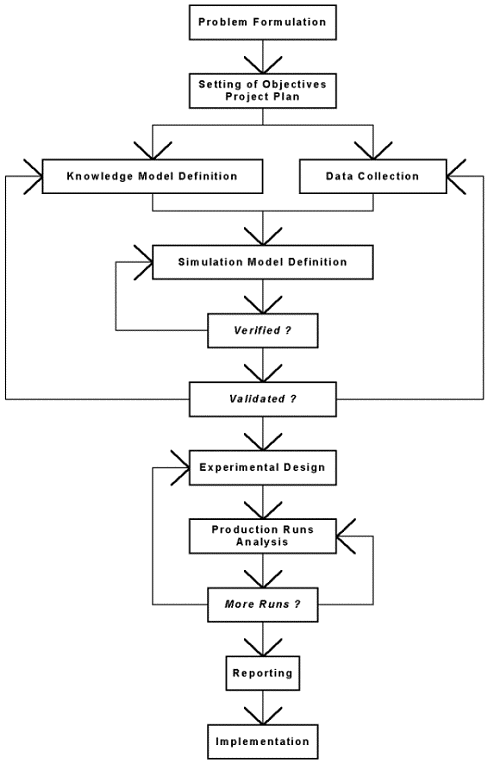 |
| Problem Formulation |
Before starting the study, a statement of the problem must be made. It is provided first by those who have the problem. The analyst must ensure that the problem described is clearly understood by both him and those who have introduced the problem. Although not shown in Figure 16, the problem can be reformulated in the study.
| Setting of Objectives and Project Plan |
The objectives indicate the questions that must be answered. At this stage, the simulation can be envisaged as the methodology to solve the problem. In this case, a statement of alternative systems to be considered can be defined. A project plan is established, including the number of persons requested for the study, the length of each phase of the work, the cost of the study...
| Knowledge Model Definition |
At this phase, a knowledge model is built. It must consider the objectives previously stated. The model is usually built progressively, including more and more details. However, the model complexity must not exceed that required for the purpose of the problem. The violation of this principle adds model building and computer expenses. At this stage, the problem is better understood, which can conduct to the reformulation of the problem or to the redefinition of the objectives and the project plan.
| Data Collection |
The kind of data that is requested is directly related to the objectives of the study. But, this stage is strongly related to the building of the knowledge model. As the complexity of the knowledge model changes, the nature of the data to collect in the real system may also change. Moreover, the collection of data is a process that usually takes a lot of time so the sooner it starts, the better. Usually, the data collection and the building of the knowledge model progress simultaneously.
| Simulation Model Definition |
When the knowledge model is built and the data collected, or at least the exact nature of the information completely identified, the writing of the simulation model can begin. At this step, simulation software must be chosen, if the resolution of the model requests a computer.
| Verification |
This step consists in verifying that the computer program performs properly. In other words, is the computer program the exact translation of the knowledge model ? Usually, with complex systems, it is difficult, if not impossible, to translate a model successfully without a good deal with debugging.
| Validation |
The problem here is to be sure that the model is an accurate representation of the real system. Validation is usually performs through the calibration of the model. It consists in an iterative process of comparing the model with the system and adjusting parameters. Of course if the validation fails, the data collected and/or the knowledge model can be reconsidered.
| Experimental Design |
Different scenarios, "experiments", will be simulated. For each one, the model is prepared by defining the "input" data of the model, the parameters of the model and different other parameters specific to the simulation like the length of the simulation, the number of "replications"... For stochastic models, we deal with random variables and for this reason, we need to run several times a same experiment, in order to have a set of values for each random variable to estimate. Then, statistical analysis will provide an estimation of the random variables according to a confident interval. A specific run of an experiment is called a replication. Of course, the more the number of replications is important, the more the estimations of the random variables are accurate (supposing the random number generator is good enough). These aspects are explained more precisely further in the presentation of VSE, when describing VSE Simulator.
| Production Runs and Analysis |
Then, for each experiment, the simulation model is executed. Observations are made and data is collected, the "output" data. Then an analysis of them is performed. At this step, new experiments or other replications can be decided.
| Reporting |
At this step, different kinds of document are provided concerning the progress of the study, the simulation program and the results of the simulations. Usually, the reporting concerning the progress of the study is periodic and does not occur just at the end of the study. All these documents are important for a further use of the models as well as for further studies. This allows modifying the simulation model more easily and offers references for the next studies. The approximation of the cost, the resources and the time requested for a new project will be better.
| Implementation |
Finally, according to the results of the simulations, decisions are made concerning the real system. Of course, the success of the phase depends on how the whole study has been managed and how the policy makers who take finally the decision have been involved in the project. It seems better that they have been regularly involved in the study, in order to understand what was going on and to be able to detect any deviation from the real objectives that analysts are not always able to see perfectly.
| DISCRETE-EVENT SIMULATION |
| Introduction |
Mathematical models can be solved by simulation and the kind of simulation we are interested in here is called "discrete-event". Simulation models are usually dynamic, they integrate the notion of time. Hence we will see in this section the notion of discrete-event, how the time is represented in a simulation model and how such a simulation is managed. For that, we will see that it depends on the "world view" used to build the model. Finally, we will present the essential components of a simulation program and its main steps.
| Discrete-Event |
In a discrete-event simulation, events occur at a specific point of the time. This is the reason they are called "discrete-events". An event can be scheduled, i.e. an activity will explicitly induce an event. For instance, the arrival of people in a room is usually implemented by the following technique. The arrival of the first person is scheduled at a given time in the simulation. When the person arrives, the arrival of the next person is scheduled by planning another event. When this event occurs, the second person arrives and the next arrival is scheduled and so on. Another way events can occur is because of a set of conditions being true, i.e. certain conditions can induce an event. Finally, an event is usually associated with an activity. According to those statements, different approaches are used to build a simulation model, they are called "world views" ([Banks 96]). Before presenting them, let us see how the time is represented in a simulation model.
| Representation of the Time |
In simulation models, the time is usually represented by a real number. Its value is usually increased to simulate the advance of the time. It is called "simulation clock" or "simulation time". No connection exists between the computation time, time needed to perform the instructions of the simulation program, and the simulation time. That induces an advantage or a drawback of simulation. If the simulation time advances faster than the computation time that means the model evolves faster than the real system, which is usually a good thing. On the other hand, simulation may be useless because the simulation evolves slower than the real system. However, in some simulations, the aim is to be slower than the real system. This is the case for instance when simulating interaction between atoms where phenomena can be very fast and so impossible to observe.
Two techniques are used to make the time progress. The first is called "fixed-increment" time advance and is easy to implement, whereas the second one is called "next-event" time advance and requests more complex algorithms and data structures to be managed ([Law 82]).
| Fixed-Increment Time Advance |
This first technique consists in incrementing the time by regular steps. A gap of time is chosen according to the frequency of the events. This method is really easy to implement but induces a lot of computing, because the time advances uniformly and at each advance, tests will be performed to find events that occur. That means lots of tests will be done for nothing during the periods of inactivity of the system. Hence, this method is usually used when some events occur with a given frequency, but the main interest of this technique is for continuous simulation ([Law 82]).
| Next-Event Time Advance |
This second technique is based on the fact that nothing happens between two events, i.e. the state of the system does not change. The idea is to manage a list of the events to occur. The time is always advanced to the sooner next event. By this way, the periods of inactivity of the system are skipped contrary to the fixed-increment time advance. Then, at each advance, activities associated with the events are performed, new events can be scheduled and then, the time is advanced to the sooner next event, and so on.
This technique is more efficient than the fixed-increment time advance, tests are only performed when a change in the system may occur. However, this method is more difficult to implement and needs a way to manage efficiently the list of events. Usually, this method is associated with discrete-event simulation, whereas the fixed-increment time advance is used by continuous simulation.
| World Views |
World views are the different approaches used to build a simulation model. In fact, they introduce different ways to see a real system. There are three kinds of approach called "event-scheduling", "process-interaction" and "activity-scanning" world views. A mixture of the event-scheduling and the activity-scanning world views is also proposed in an approach called "three phases" ([Banks 96]).
| Event-Scheduling World View |
As we saw previously, we can consider events as induced by activities. This introduces the world view called event-scheduling. This approach uses the next-event advance time. Events represent the start and the end of activities. Activities can induce others activities.
| Process-Interaction World View |
With this approach, the analyst concentrates on the entities of the system and more precisely on their life cycle. This view is used due to its intuitive appeal. In fact, the analyst will describe the steps of the life of an entity, also called "process". A process is a succession of activities and events. The progression of a process represents the evolution of the entity. It can be suspended, meaning that the entity waits for an event to continue its progression. Generally, it is associated with the fact that to perform an activity, an entity needs resources. Like the event-scheduling world view, this approach implements the next-event time advance.
The object-oriented approach used for simulation is an extension of the process-interaction world view. The analyst also concentrates on the entities. Events and all the interactions are generated through the mechanism of message passing between entities.
| Activity-Scanning World View |
With this approach, events are considered induced by a set of conditions becoming true. Hence, the technique consists in checking conditions at a given time, according to the state of the system, and inducing the associated activities. Then, the time is incremented and at each progression, the same tests are performed again. Everyone agree to say that the scanning of the conditions is costly. However, this approach is more understandable and facilitates the maintaining of the model compared to the first two approaches. This method implements the fixed-increment time advance.
| Three Phases Approach |
A combination of the event-scheduling and the activity-scanning world views is proposed in an approach called three phases. Events are considered as activities of duration zero. With this definition, the activities are separated in two groups B and C. The B-type activities are those which are scheduled, preprogrammed and correspond to the event-scheduling world view. This allows next-event time advance and a list of the scheduled events is maintained. The C-type activities are those that are conditional on certain conditions being true and correspond to the activity-scanning world view.
So, the technique consists in advancing the time to the sooner event, using the list of scheduled B-type activities. All the B-type activities occurring at this time are performed and then, conditions are checked to eventually execute C-type activities. Then, the time is again incremented to the next event of the B-Type activities list, and so on. The combination of these two approaches allows the modeling of more complex resource problems than the same approaches separately.
| Components of a Discrete-Event Simulation Model |
From the previous paragraphs, we can say that a simulation model needs some generic components to work. The main elements are a clock with a time advance mechanism and a manager for the list of events, if the world view needs it. Moreover, in the case of a process-interaction, a mechanism must be provided to support the interaction of the processes, their suspension, their reactivation... Finally, in the case of stochastic simulation, components must be provided to allow the generation of random numbers, according to well-known parameterized random distributions. This last aspect must include the possibility of running exactly the same simulation several times, i.e. the random numbers generated are the same between two experiments. It must also include the possibility of replication, i.e. the random numbers generated are not the same between two replications, but the distribution of the random variables and all the other parameters are identical. Added to these essential components, efforts must be done in term of documentation, debugging and visual simulation to provide a efficient tool for simulation.
| Steps of a Simulation Program |
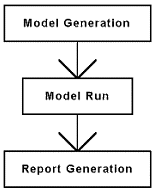
The execution of a program can be separated in three main steps ([Gordon 78]) as presented by Figure 17. The first phase is the generation of the model. The entities of the model are created, initialized and the first events may be scheduled, according to the world view considered. By this way, the model is prepared to be run. Then, the model is run, time is increased, events occur, activities are performed until the time reached a given limit or until there is no more activity to execute. This means no event matches with the conditions (in the case of an activity-scanning world view) or no event is scheduled (in the case of an event-scheduling world view). During the running, data is collected. Finally, results are reported, meaning the data collected is organized, and eventually statistical analysis is performed.
Figure 17: Steps of a Simulation Program.
 |
Among the results a simulation run can provide are the following ([Gordon 78]):
Counts, giving the number of a particular kind of entity or the number of occurrences of a particular event.
Summary measures, such as extreme values (minimum and maximum), mean values...
Utilization, which gives the percentage of time an entity is engaged in an activity.
Occupancy, which gives the percentage of time a category of entity is engaged in an activity.
Distributions of supposed random variables.
Transit times, giving the time taken for an entity or a category of entity to move from one part of the system to another.
These different kinds of measure introduce various techniques to collect the data. These methods are presented in details in [Gordon 78]. They induce an amount of code that is not always expected during the modeling of the system. Although they are the aim of the simulation, the way the results are collected is not the first preoccupation during the building of the model.
| VISUAL SIMULATION |
| Introduction |
Before the 1980s, graphics and animation in simulation where only accessible on very large computers. But since, low-priced microcomputers with good graphical capacities appear. This spreads the use of graphics and animation in simulation. Now, animation is considered as an important part in the development of a simulation model, because its contribution in most of the phases of a simulation study is significant.
Actually, there are several simulation software products associated with an animator. There are also environments that include an animator. And there are animators that are independent of simulation packages.
| Contribution of Graphic Interface and Animation in a Simulation Study |
[Hill 96] presents the importance of animation and graphic interface, and explains their contributions in the main steps of a simulation study. [Balci 98b] also underlines the importance of the animation of a simulation in the process of verification, validation and testing. The following gives a summary of those contributions ([Hill 96]).
Development and verification of the simulation model: Compared to the textual execution trace of a program, animation is obviously clearer. The programmer can detect errors more easily and can also find errors that were difficult, if not impossible, to find with a single trace. In fact, animation allows him identifying complex behavior and relationships.
Validation of the knowledge model: Animation facilitates the validation of the knowledge model, because the specialists of the real system have a better representation of the system, and understand more easily what is modeled and by this way, realize whether it is representative of the real system.
Analysis and design of the experiments: Animation offers new possibilities in the analysis of a system. In fact, added to the statistical results, the analyst can observe the evolution of the system and the transient phenomena. Moreover, a graphic interface can facilitate the modification of the model to design new experiments. For instance, instead of modifying the code, the analyst just has to drag and drop an icon, put it in the layout representing the system and connect it to other objects of the model.
Communication and presentation of the results: Animation is obviously a powerful tool to communicate. Everyone looking at the animation will understand what happens globally in the model. It is also a perfect tool for teaching. Finally, the production of graphical results is clearer and more explicit than just a list of statistical values.
That shows the importance of the animation in simulation and explains our effort and consideration for the animation in the components we have designed. Moreover, we think that animation and graphical representation is really helpful for the design and the reuse of software components.
| SIMULATION LANGUAGES AND PACKAGES |
Based on information found in [Hill 96], [Hlupic 95] and [Banks 96], we presents a brief overview of the main simulation languages and packages proposed in the market (see Figure 18). We distinguish the dedicated languages that concern a particular kind of problem from the general purpose languages that are not designed for a particular kind of problem.
Usually, the formalism of general purpose software is difficult to acquire and requests a high capacity of abstraction, unlike the dedicated simulation languages that use directly the terminology of the domain, so their learning is simplified.
Figure 18 presents only the general purpose simulation languages. Then, a distinction is made between OO languages such as MODSIM, QNAP, Simple++, SIMULA, VSE and languages such as GPSS, SIMAN, SIMSCRIPT, SLAM that use the classical world views of process-interaction and event-scheduling. To deal with the difficulty of the general purpose languages, packages or libraries are usually provided for a given category of problem. For this purpose of reusability, the OO approach seems to offer more possibilities than the classical approaches. Finally, most of them provide a graphic environment and an animator, either directly in the software or in a separate application.
Figure 18: General Purpose Simulation Languages.
| Language | Process-Interaction Word View |
Event-Scheduling World View |
Object-Oriented | Type of Simulation |
| GPSS | X | Discrete | ||
| MODSIM | X | Discrete | ||
| QNAP | X | Discrete | ||
| SIMAN | X | X | Discrete and continuous | |
| Simple++ | X | Discrete | ||
| SIMSCRIPT | X | X | Discrete | |
| SIMULA | X | Discrete | ||
| SLAM | X | X | Discrete | |
| VSE | X | Discrete |
| CONCLUSION |
After the presentation of the OO approach and discrete-event simulation, it seems logic to discuss the methods and methodologies proposed to deal with the modeling of complex systems. However, we will not present them. Our analysis and design of reusable components just concern parts of a system and are not complex enough to necessitate a full method. Moreover, the tools offered by VSE are good enough to represent clearly the object and the class structures. For this reason, we only use a small part of the Unified Modeling Language (UML) to conduct our study ([OMG Web]).
But a presentation of the main OO methods is provided in [Hill 96]. This book introduces also the concepts of modeling environment and methodology. A presentation of the SMDE modeling environment, that has inspired VSE, is also presented in [Balci 92].
To resume, the Visual Simulation Environment (VSE) is an object-oriented, discrete-event simulation software allowing a visual simulation and integrating a fully graphic interface for the design of the model and the experimentation, the running and the analysis of the simulation.
|