 |
8. REUTILISABILITE POUR LES PROBLEMES DE GRAPHES |
Dans le début de cette partie nous avons tenté de montrer l'intérêt de développer des composants réutilisables pour la recherche opérationnelle et d'expliquer les possibilités, avec leurs avantages et leurs défauts, offertes par la programmation orientée objet choisie pour notre conception. De ces constats et de notre propre expérience du développement d'une bibliothèque réutilisable dans le cadre de notre étude des problèmes de synchronisation hypermédia, nous présentons dans ce dernier chapitre quelques réflexions concernant différentes solutions de conception.
L'enjeux étant important, quelques tentatives ont naturellement déjà vu le jour, avec plus ou moins de succès. Une liste relativement complète peut être trouvée dans [Macowicz97]. Dans notre discussion, nous ne retenons qu'un échantillon de bibliothèques C++ dont la réutilisabilité est avérée, puisqu'elles sont employées dans différents projets: LEDA (Library of Efficient Data types and Algorithms [ASWeb], débutée en 1988), BGL (Boost Graph Library [SiekWeb], débutée en 1998) et GTL (Graph Template Library [ForsterWeb], débutée en 1999). Chacune est le fruit de choix de conception différents liés aux objectifs auxquels elle a été assignée.
Il faut alors préciser que notre bibliothèque, la B++ Library [BacheletWeb], débutée en 1999, a pour but de satisfaire à la fois des néophytes en matière de recherche opérationnelle (i.e. une réutilisation boîte noire), et des personnes averties (i.e. une réutilisation boîte blanche). Dans la première situation, il s'agit de permettre à une personne capable de modéliser un problème sous la forme d'un graphe d'implémenter sa résolution aisément, sans connaissances particulières de la recherche opérationnelle. Dans la seconde situation, notre volonté est de permettre un prototypage rapide d'une méthode de résolution. Nous espérons également, à travers un développement homogène, favoriser la comparaison de l'efficacité pratique de différents algorithmes.
La première partie de ce chapitre présente diverses manières de concevoir des composants génériques, c'est-à-dire les plus indépendants et les plus extensibles possibles. Nous nous intéressons en particulier aux structures de données et aux algorithmes. Dans un premier temps, nous discutons de la structure d'un graphe et des possibilités de la rendre paramétrable sur les données portées par les noeuds et les arcs. Nous présentons ensuite différentes manières d'abstraire une structure de données dans un algorithme. Enfin, nous expliquons comment permettre l'extensibilité d'un algorithme. Nous terminons cette discussion sur un problème qui semble plus secondaire, mais qui est en fait très courant: la gestion de données additionnelles sur un graphe nécessaires à la plupart des algorithmes pour leur exécution. Pour tous ces problèmes de conception, nous ne proposons en aucun cas de solution absolue, mais tentons d'expliquer au mieux les forces et les faiblesses de chacune des principales possibilités.
Dans une seconde partie, nous présentons succinctement notre bibliothèque. Il s'agit de la conclusion de notre discussion sur la conception de composants réutilisables pour la recherche opérationnelle. Nous exposons ainsi l'état d'avancement de notre bibliothèque en proposant un aperçu rapide des principales fonctionnalités liées à la réutilisabilité que nous n'avons pas traitées jusqu'à présent. Ces points concernent très certainement des aspects plus pratiques de la réutilisabilité, notamment la portabilité, qu'il semble néanmoins important de souligner pour les personnes désireuses de se lancer dans une telle entreprise. Cette présentation permet de situer notre bibliothèque dans l'objectif à plus long terme de concevoir un environnement de développement pour les problèmes de graphes, dont nous proposons en fin de discussion une rapide ébauche.
| 8.1. GENERICITE DES STRUCTURES DE DONNEES |
Penchons-nous tout d'abord sur les différentes façons de modéliser la structure d'un graphe. La figure 8.1 montre de manière très générale comment représenter en orientation objet cette structure. Nous considérons ici que le graphe est composé (au sens objet) d'arcs et de noeuds, il est donc chargé de les gérer entièrement. Nous ne nous intéressons pas à la représentation même du graphe, c'est-à-dire si le graphe est représenté par une matrice d'adjacence, une matrice d'incidence, une liste d'adjacence (cf. chapitre 2)... Notre propos est justement de discuter d'une manière qui permet d'abstraire de tels détails pour les algorithmes. Ces derniers doivent être applicables indépendamment de la structure véritable du graphe, et ce avec le maximum d'efficacité.
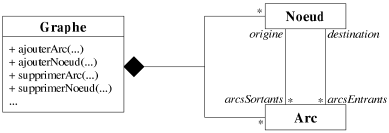 |
| Figure 8.1: Représentation générique d'un graphe. |
Dans un premier temps, nous nous intéressons à l'extensibilité de la structure. Il est en effet indispensable que l'on puisse créer un graphe et le manipuler avec n'importe quelles données sur ses arcs et ses noeuds. Par exemple, si l'on traite un problème de plus court chemin, le graphe portera des informations géographiques (distances, coordonnées...), alors que pour un problème de flot il portera plutôt des informations de flux (capacités, demandes...). L'utilisateur ne doit coder que ces données additionnelles, et ne doit en aucun cas avoir à toucher à la structure même du graphe. Dans cette optique, nous proposons deux manières de représenter la structure d'un graphe: une approche par héritage et une approche par patrons. Une fois que nous aurons jugé de la meilleure modélisation pour nos besoins, nous rappelons une technique très connue pour masquer la structure même du graphe (matrice, liste...), qui est la première étape dans l'indépendance des algorithmes par rapport aux structures de données qu'ils manipulent.
| 8.1.1. Modélisation d'un graphe par héritage |
La première manière de représenter un graphe extensible consiste à
reprendre la structure générique présentée à la figure 8.1, en
ajoutant aux arcs et aux noeuds un attribut supplémentaire qui représente les
données, outre les informations structurelles du graphe, qu'ils peuvent porter (cf. figure
8.2). Pour les arcs, cet attribut serait de la classe DonnéeArc et pour les
noeuds de la classe DonnéeNoeud. L'unique rôle de ces deux classes est
d'être étendues, c'est-à-dire que l'utilisateur puisse définir ses
propres données en héritant de ces deux classes. La manipulation est donc très
simple, l'utilisateur a seulement à définir une classe qui hérite de
DonnéeArc ou DonnéeNoeud, possédant les attributs
représentant les données qu'il souhaite attribuer aux arcs ou aux noeuds du graphe.
Dans notre exemple, nous avons ajouté sur les arcs des données de flot et sur les
noeuds un potentiel. On pourrait penser que le défaut majeur de cette structure est
l'inefficacité liée à l'héritage. Cependant le mécanisme de
virtualité n'est pas utilisé ici, tout du moins pour l'accès aux
données ajoutées (en effet, il est possible par exemple d'avoir une méthode
virtuelle qui se charge d'afficher les données contenues dans un objet
DonnéeArc). Le défaut de cette approche se trouve néanmoins dans
l'accès aux données de flot d'un arc.
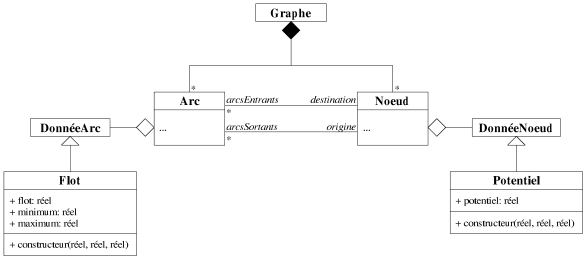 |
| Figure 8.2: Représentation d'un graphe avec une approche par héritage. |
En effet, l'arc est de type Arc, son attribut donnée est donc
de type DonnéeArc. Mais cette classe ne possède pas, par exemple,
l'attribut flot. Il faut alors transformer donnée en un objet de
type Flot. Autant la conversion d'une sous-classe vers l'une de ses super-classes
(appelée souvent upcast) est instantanée (puisque l'objet appartient
forcément à la classe dans laquelle on veut le transformer), autant la conversion
d'une super-classe vers l'une de ses sous-classes (appelée souvent downcast)
demande vérification. Les langages permettent naturellement le downcast, mais sa
vérification ne peut être effectuée qu'à l'exécution. Cela
signifie donc une perte de temps à chaque accès aux données, même si le
programmeur est sûr de la conversion. L'exemple suivant tente d'illustrer la
problématique exposée ici.
Graphe * g = new Graphe(...);
Flot * f = new Flot(...);
DonnéeArc * d = new DonnéeArc(...);
g.ajouterNoeud(1);
g.ajouterNoeud(2);
...
g.ajouterArc(1,2,f);
g.ajouterArc(2,5,d);
...
(Flot)(g.getArc(1,2)).flot() = 8;
(Flot)(g.getArc(2,5)).flot() = 3;
Un graphe g est créé avec notamment l'arc (1;2) qui porte des
données de flot et l'arc (2;5) qui ne porte aucune donnée additionnelle. Les
deux dernières lignes de l'exemple tentent d'affecter un réel au flot des deux arcs
cités précédemment, en effectuant une conversion (représentée
par (Flot)). Pour l'arc (1;2) l'action réussit, alors que pour
(2;5) elle échoue naturellement. Et cette erreur ne peut être vue qu'à
l'exécution du programme.
Mais la virtualité, et surtout l'inefficacité qu'elle peut engendrer, ne sont pas
pour autant exclues de cette modélisation. Avec cette approche, un algorithme est
dépendant des types des données portées par le graphe. En effet, dans
l'exemple précédent, le code manipule explicitement des objets de la classe
Flot. Si l'on souhaite utiliser ce code avec une classe différente, en voulant
par exemple ajouter une tension sur l'arc, on est obligé d'étendre la classe
Flot par héritage. Tant que l'on ne tente pas de surcharger une méthode
de cette classe, aucun coût supplémentaire n'est à noter. En revanche, si le
flot qui était un simple attribut devient une valeur calculée, alors il faut que la
méthode qui retourne le flot dans la classe Flot soit virtuelle pour qu'une
sous-classe puisse la surcharger. L'accès au flot entraîne alors un appel au
mécanisme de virtualité dont nous connaissons les problèmes.
En résumé, la modélisation du graphe avec une approche par héritage entraîne une perte de temps due au downcast, certes plus faible que la virtualité. Cependant, en observant de plus près les algorithmes qui manipulent cette structure, on s'aperçoit que les méthodes d'accès aux données des noeuds et des arcs doivent être le plus souvent virtuelles afin de permettre une plus grande réutilisabilité des algorithmes. Tous les défauts que nous avons énumérés ici portent sur l'efficacité de la modélisation. Il faut tout de même noter que l'effort à fournir ici pour décrire les données portées par le graphe est minimal et que cette représentation permet, contrairement à celle qui suit, de stocker des données de types variés sur les arcs et les noeuds du graphe, ce qui offre une certaine souplesse qui peut être appréciable, non pas pour la recherche opérationnelle, mais pour la simulation par exemple (cf. [Bachelet98]).
| 8.1.2. Modélisation d'un graphe par patrons |
Nous cherchons donc une modélisation d'un graphe qui permette d'ajouter des
données sur les arcs et les noeuds tout en garantissant une indépendance des
algorithmes par rapport au type de ces données. Nous proposons une représentation
sous forme de patrons où les paramètres sont les classes des données
portées par les arcs et les noeuds, notées respectivement TA et
TN sur la figure 8.3. Comme dans la modélisation par héritage, les arcs
et les noeuds possèdent un attribut donnée qui représente les
données qu'ils portent.
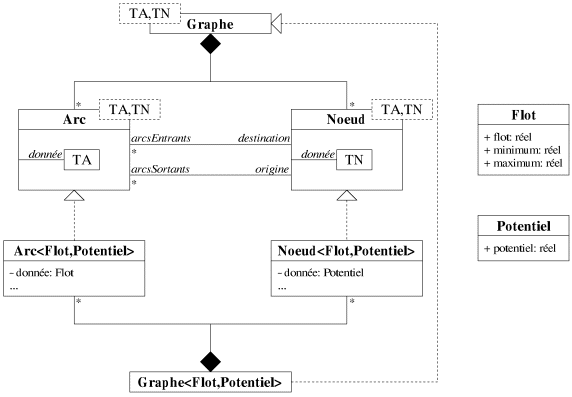 |
| Figure 8.3: Représentation d'un graphe avec une approche par patrons. |
Pour créer un graphe avec les données qu'il souhaite, un utilisateur doit
simplement créer les classes représentant ces données, dans notre exemple
Flot et Potentiel, et ensuite instancier le graphe avec ces deux classes.
L'avantage de cette structure est celui de tout patron, aucun coût n'est ajouté par
rapport à l'opération manuelle qui consisterait à répliquer et à
modifier la structure de graphe pour chaque type de données.
En ce qui concerne les algorithmes, il est tout à fait possible comme nous le verrons par la suite d'écrire un patron d'algorithme paramétré sur les types des données portées par le graphe, le patron supposant implicitement que les types implémentent certains concepts. Ces derniers seront vérifiés au moment de la compilation. Nous avons ainsi l'indépendance minimale que nous recherchions depuis le début, i.e. un algorithme conçu pour certains types de données sur les arcs et les noeuds peut fonctionner pour d'autres types. Nous allons nous intéresser dans la dernière partie de cette section à renforcer l'indépendance de l'algorithme par rapport aux structures de données qu'il manipule, en particulier celle du graphe.
Mais avant cela, revenons rapidement sur les bibliothèques que nous avons présentées en début de chapitre. LEDA, comme BGL et notre bibliothèque, ont opté pour une modélisation par patrons avec certes des différences, mais avec la même idée principale d'abstraction. En revanche, GTL propose une représentation proche de celle par héritage, mais ne préconise même pas l'héritage pour attribuer des données aux arcs et aux noeuds, et propose plutôt de construire des listes à part de la structure de graphe, supposant que les noeuds et les arcs sont ordonnés (ce qui empêche tout modification structurelle du graphe). Les raisons qui font que GTL est réutilisable correspondent donc à un type d'utilisation différent de celui qui nous intéresse ici.
| 8.1.3. Abstraction par les itérateurs |
Dans beaucoup de traitements, les structures de données qui sont manipulées sont des collections d'objets (liste, tableau, pile, file d'attente, arbre...). En particulier le graphe possède deux collections, l'une d'arcs et l'autre de noeuds. Nous discutons ici d'une manière d'abstraire la structure même de ces collections, afin que les traitements sur celles-ci soient indépendants de la structure de données effectivement manipulée. Les approches présentées ici peuvent être étendues à l'abstraction de tout type de structure de données.
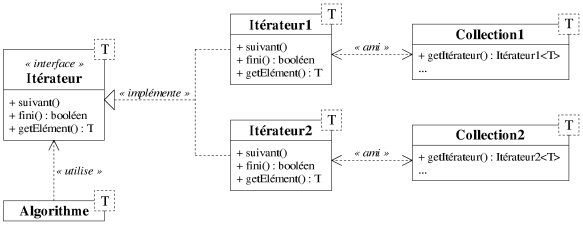 |
| Figure 8.4: Un exemple d'itérateur. |
Dans notre discussion, nous considérerons l'exemple d'une procédure qui parcours tous les éléments d'une collection et leur applique un traitement, et nous nous intéresserons à rendre son code unique pour tout type de collection. Le principe consiste à intercaler, pour chaque collection, une classe entre la collection et les algorithmes qui la manipulent. Cette classe possède la même interface quelque soit la collection. En l'utilisant de préférence aux méthodes propres à la collection, les algorithmes deviennent plus indépendants de la structure qu'ils manipulent et les collections plus facilement interchangeables. L'interface qui convient à notre exemple est un itérateur, il s'agit d'un patron de conception proposé dans [Gamma95] et exploité intensivement dans la bibliothèque STL.
L'interface d'un itérateur propose la fonctionnalité de déplacement dans
une collection triée (implicitement ou explicitement). La figure 8.4 montre le principe d'un
itérateur qui offre les méthodes pour se déplacer dans un sens arbitraire d'un
élément à un autre d'une collection. Dans notre exemple, nous disposons de
deux collections qui peuvent créer un ou plusieurs itérateurs (grâce à
leur méthode getItérateur()) sur leur propre structure.
Il est à noter qu'une collection doit accéder à des attributs normalement
cachés pour initialiser un itérateur et inversement un itérateur doit
accéder à la structure cachée de sa collection. Les deux classes doivent donc
être mutuellement amies, cela signifie que chacune autorise explicitement l'autre
à accéder à ses données cachées (tous les langages
n'implémentent pas cette fonctionnalité, en C++ il existe le mot-clé
friend qu'une classe peut utiliser pour en autoriser une autre à accéder
à ses données cachées, en Java cette fonctionnalité n'est pas
directement implémentée, mais par le mécanisme de classe interne, il
est possible que certaines classes voient des choses normalement cachées pour d'autres).
Nous présentons maintenant différentes manières d'utiliser les
itérateurs qui traduisent différents niveaux d'abstraction d'une collection pour un
algorithme.
| 8.1.3.1. Abstraction par les itérateurs |
Le premier niveau d'abstraction consiste, même si l'on connaît
précisément une structure, par exemple un objet de la classe
Collection1, à utiliser ses itérateurs pour le manipuler, en
évitant les méthodes propres à la structure. Comme le montre l'exemple
suivant, il est ainsi possible, même dans un code a priori non réutilisable, de
modifier la structure de données sans modifier aucune autre ligne de code.
Collection1<T> c = ...;
Itérateur1<T> i = g.getItérateur();
while not i.fini() do
...i.getElément()...
...
i.suivant();
end while;
Si l'on remplace les classes Collection1 et Iterateur1 par les
classes Collection2 et Itérateur2, aucune autre ligne n'a besoin
d'être modifiée pour que le code fonctionne encore. Cette première abstraction
d'une structure de données est intéressante mais insuffisante puisqu'elle
nécessite une intervention manuelle, néanmoins il est toujours conseillé
d'employer cette approche qui ne coûte absolument rien en efficacité, ni même en
temps de développement et qui, à défaut d'une meilleure approche, apporte une
certaine maintenabilité au code.
| 8.1.3.2. Abstraction par paramétrage des itérateurs |
Le second niveau d'abstraction consiste à paramétrer un algorithme sur les
classes des itérateurs qu'il manipule. En reprenant l'exemple précédent, il
est possible de proposer un algorithme paramétré sur le type de l'itérateur
utilisé, le paramètre I dans l'exemple qui suit. L'algorithme n'aura
aucune connaissance de la structure qu'il manipule et n'utilisera que les itérateurs qui lui
sont fournis en argument.
function algo<I>(I * i)
while not i.fini() do
...i.getElément()...
...
i.suivant();
end while;
end function;
L'algorithme nécessite alors simplement un paramètre qui implémente le concept d'itérateur pour fonctionner. L'inconvénient de cette approche est que l'utilisateur de l'algorithme connaît des détails du fonctionnement interne de la fonction (dans notre cas, que l'algorithme parcours un à un les éléments), ce qui peut rompre le concept d'encapsulation. En outre, si l'algorithme a besoin de beaucoup d'itérateurs, l'utilisateur doit les fournir, sans forcément en comprendre les raisons. Cette approche a été celle choisie par la STL, mais il faut reconnaître que les inconvénients que nous venons de citer ne s'y appliquent pas, puisque le transfert d'itérateurs aux algorithmes est justifié.
| 8.1.3.3. Abstraction par paramétrage de la structure de données |
Aux vues des inconvénients des approches précédentes, un troisième niveau d'abstraction a été proposé notamment dans [Lee99a], qui a suivi les premiers travaux de [Kuhl96a] (utilisant plutôt le second niveau d'abstraction), et a débuté la conception de la bibliothèque BGL.
 |
| Figure 8.5: Un exemple d'abstraction d'une collection. |
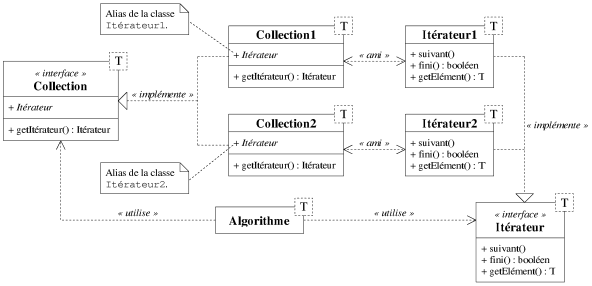
Au lieu de paramétrer l'algorithme sur les itérateurs, pourquoi ne pas le paramétrer sur la structure de données même qui doit être manipulée. La structure doit alors implémenter un concept qui permet la création d'itérateurs pour la parcourir. La figure 8.5 montre l'interface que doit posséder une collection. Mais il faut tout de même que l'algorithme connaisse le type de l'itérateur qu'il manipule. Comme on ne souhaite pas fournir explicitement d'itérateur en paramètre à l'algorithme, il ne peut y avoir que la collection qui possède ce renseignement. Pour cela, il est possible de définir des types internes à une classe qui sont accessibles comme toute autre propriété de la classe.
En reprenant notre exemple, le type interne Itérateur
(représenté en italique sur la figure) est défini dans l'interface
Collection, il s'agit en fait d'un alias sur la véritable classe de
l'itérateur de la collection. Dans la classe Collection1, il s'agit donc du
type Itérateur1. L'exemple suivant illustre cette manière d'abstraire la
structure de données. Cette approche fournit une abstraction complète, les
collections sont simplement obligées d'implémenter un certain concept relatif au
mécanisme des itérateurs.
function algo<C>(C * c)
c.Itérateur i = c.getItérateur();
while not i.fini() do
...i.getElément()...
...
i.suivant();
end while;
end function;
Le seul véritable défaut de cette approche (également présent dans
le deuxième niveau d'abstraction) se situe au niveau pratique. Il est en effet très
difficile de déboguer un patron d'algorithme élaboré avec ce type de
paramètre. La raison en est très simple. Lorsque le patron est analysé
à la compilation, avant toute instanciation, le type C, si l'on revient
à l'exemple précédent, est inconnu. Il est donc impossible de vérifier
que le type C.Iterateur (ou le type I pour l'exemple du deuxième
niveau d'abstraction) existe et surtout implémente le concept d'itérateur. Il faut
donc attendre une instanciation du patron pour démarrer une véritable
vérification du code. Ceci est très problématique lorsque l'on possède
de nombreux modules à compiler et que le patron se trouve tôt dans la compilation
alors que son instanciation s'effectue très tard. La phase de débogage, par la
longueur des tentatives de compilation, devient rapidement presque impossible. En revanche, en tant
qu'utilisateur, cette dernière approche présente la meilleure alternative,
puisqu'elle offre le plus d'indépendance entre un algorithme et les structures de
données qu'il manipule.
| 8.1.3.4. Un compromis d'abstraction |
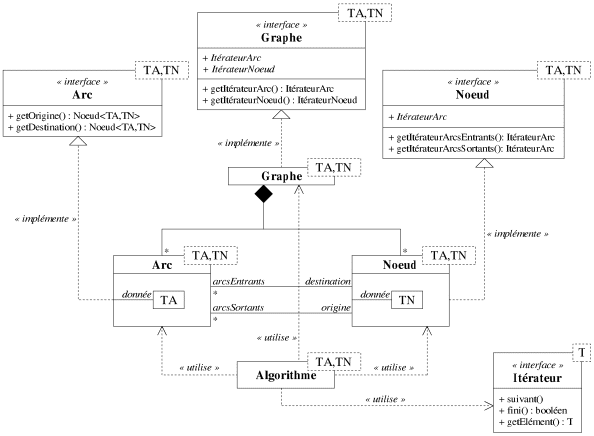
Comme précisé précédemment, la bibliothèque BGL propose cette dernière approche qui satisfait pleinement les utilisateurs, mais rend la tâche de la conception de la bibliothèque difficile. LEDA ne semble pas poursuivre tout à fait le même objectif de rendre les structures de données indépendantes des algorithmes. Sa manière de concevoir les composants se rapproche de notre choix, puisque nous proposons une abstraction intermédiaire qui tente de satisfaire à la fois les concepteurs (qui sont aussi réutilisateurs) et les utilisateurs finaux. Considérons l'exemple suivant qui illustre notre approche.
function algo<TA,TN>(Graphe<TA,TN> * g)
g.ItérateurArc i = g.getItérateurArc();
while not i.fini() do
...i.getElément()...
...
i.suivant();
end while;
end function; Il est possible de paramétrer les algorithmes sur les types des données
portées par les noeuds et les arcs, et dans l'algorithme d'appliquer le tout premier niveau
d'abstraction, c'est-à-dire manipuler directement la classe Graphe pour
récupérer, à la manière du troisième niveau d'abstraction, les
classes des itérateurs. L'algorithme n'est alors pas vraiment indépendant de la
structure de graphe, puisqu'il manipulera toujours la classe Graphe. Cependant, toutes
les manipulations se font par les itérateurs. Ainsi, un utilisateur qui désire
changer de structure de graphe peut le faire sans avoir à modifier autre chose. Mais cela a
un impact sur toute la bibliothèque, puisqu'il ne peut exister qu'une seule classe
Graphe.
 |
| Figure 8.6: L'abstraction d'un graphe. |
Notre bibliothèque est ainsi nettement moins flexible, mais lorsque nous nous penchons sur la manière de réutiliser les algorithmes, on s'aperçoit qu'il est très délicat de manipuler plusieurs structures de graphe. Imaginons que l'on soit en train d'élaborer une nouvelle méthode, basée sur des algorithmes existants. Si l'un des algorithmes fonctionne efficacement avec une structure de graphe et un autre avec une structure totalement différente, quelle structure choisir pour notre méthode ? Celle de l'un des deux algorithmes existants ou une structure qui sera un compromis pour les deux algorithmes ? L'utilisateur se trouve alors confronté à un dilemme pour lequel il ne possède pas tous les détails; et d'ailleurs dans un souci d'encapsulation, il ne doit pas. Il connaît tout au plus quelle structure est la mieux adaptée à un algorithme.
Ainsi, pour l'utilisation que nous envisageons de notre bibliothèque, un développement rapide de prototypes et une vitesse raisonnable des algorithmes pour un produit fini, nous avons choisi de fixer la structure de données du graphe. Nous détaillons légèrement en annexe notre choix. La figure 8.6 résume finalement le modèle que nous avons retenu. Certes il n'est pas le meilleur mais sans une évolution notable des compilateurs C++ sur la vérification des patrons, il nous semble peu envisageable de maintenir une bibliothèque comme la nôtre avec une abstraction totale de la structure d'un graphe.
| 8.2. GENERICITE DES ALGORITHMES |
Nous abordons ici la généricité même des algorithmes. Les manières de rendre un algorithme indépendant des structures de données qu'il manipule ont été discutées à la section précédente. Nous présentons maintenant une façon de le concevoir plus indépendant des sous-algorithmes qu'il emploie. Ensuite, nous discutons de différentes approches pour le rendre paramétrable, afin qu'il soit extensible ultérieurement. Pour des raisons de clarté, les figures de cette section ne présentent pas les algorithmes sous forme de patrons comme il l'a été décidé à la section précédente, nous considérons implicitement qu'ils sont paramétrés sur les données portées par les noeuds et les arcs.
| 8.2.1. Abstraction des algorithmes |
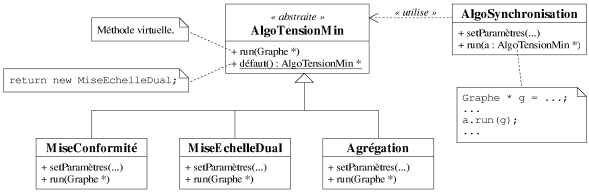
Il existe un patron de conception très connu, appelé stratégie (cf.
[Gamma95]), qui consiste à modéliser un algorithme sous la
forme d'un objet possédant une méthode, run() par exemple,
appelée pour exécuter l'algorithme. Il est alors possible de proposer une classe
abstraite pour représenter une catégorie d'algorithmes (e.g. les algorithmes pour
résoudre le problème de la tension de coût minimale, cf. chapitre 4).
 |
| Figure 8.7: Un exemple d'abstraction d'une catégorie d'algorithmes. |
Comme le montre la figure 8.7, cette classe abstraite fournit une interface commune à
tous les algorithmes, ce qui les rend totalement interchangeables lorsqu'ils sont ensuite
utilisés dans un autre algorithme, e.g. la classe AlgoSynchronisation sur la
figure. La virtualité impliquée ici est négligeable dans la plupart des cas,
puisque les méthodes appelées ainsi sont des algorithmes complets, i.e. avec un
nombre d'opérations nettement supérieur à celui induit par la
virtualité. En outre, l'interface étant commune à tous, elle ne peut pas
être utilisée pour fournir des paramètres spécifiques à un
algorithme. Au patron stratégie, il faut donc ajouter pour chacun une méthode propre,
e.g. setParamètres(), dont le rôle est d'initialiser les
paramètres de l'algorithme.
AlgoTensionMin * a = new
MiseConformité;
AlgoSynchronization * s = new AlgoSynchronisation;
s.setParamètres(...);
a.setParamètres(...);
s.run(a);
L'exemple précédent montre qu'il est ainsi possible de décider de
l'algorithme de tension de coût minimal à employer pendant l'exécution du
programme, de le créer et de le paramétrer avant de le fournir à l'algorithme
AlgoSynchronisation. Il faut noter que le rôle des méthodes
setParamètres() peut être joué par les constructeurs des
algorithmes. Ainsi, au moment de leur création ces derniers sont systématiquement
paramétrés.
Il semble également important, lorsque l'on dispose de plusieurs méthodes pour
résoudre un même problème, d'en fournir une par défaut, afin
d'éviter que l'utilisateur ne se perde dans des détails inutiles sur les performances
des algorithmes. C'est le rôle de la méthode de classe défaut() de
AlgoTensionMin, qui fournit a priori l'algorithme reconnu le plus performant. Mais il
est tout à fait possible d'envisager une approche plus évoluée où
défaut() reçoit le graphe à traiter en paramètre, et
à partir d'une analyse (e.g. la mesure de la densité du graphe) propose l'algorithme
le mieux adapté. Cette méthode de classe est également importante pour
l'évolution des programmes des utilisateurs. En l'utilisant un composant
bénéficie automatiquement des progrès apportés par l'intégration
d'une nouvelle méthode plus performante dans la bibliothèque.
| 8.2.2. Extension des algorithmes |
Nous proposons ici trois manières de rendre un algorithme extensible, l'idée étant que certaines parties de l'algorithme sont déléguées dans des méthodes qui peuvent être remplacées par le réutilisateur. Dans la suite de notre discussion, même si les figures ne le montrent pas toujours, nous considérons que les algorithmes suivent le patron stratégie, avec les évolutions proposées à la section précédente, à savoir une méthode pour paramétrer chaque algorithme et une méthode de classe qui fournit l'algorithme le mieux adapté.
| 8.2.2.1. Approche par méthode virtuelle |
La première approche, le patron de conception méthode paramètre
(template method [Gamma95]), consiste tout simplement, de la
méthode run() d'un algorithme, à déporter une partie du code dans
des méthodes virtuelles, les méthodes paramètres, appartenant toujours
à l'algorithme. Ainsi, par héritage, ces méthodes peuvent être
modifiées, et sans altérer le code de la méthode run() peuvent
changer son comportement. La figure 8.8 illustre ce mécanisme.
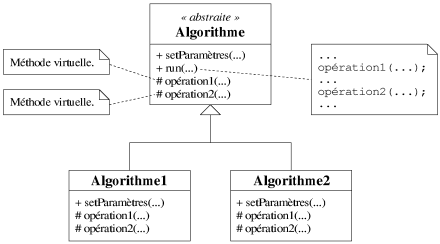 |
| Figure 8.8: Un exemple d'extension d'un algorithme par méthodes virtuelles. |
Le défaut majeur de cette approche est évidemment l'emploi du mécanisme de virtualité qui peut, si les méthodes paramètres sont souvent appelées, entraîner une perte de performance conséquente. Le second défaut de cette technique est la rigidité de l'extension de l'algorithme. Il est en effet impossible en temps réel de proposer un paramétrage différent de ceux prévus par les sous-classes de l'algorithme.
| 8.2.2.2. Approche par visiteur abstrait |
La seconde approche repose sur le concept de visiteur, également un patron de
conception proposé dans [Gamma95]. Il consiste à
modéliser les méthodes paramètres comme un objet. Plus
précisément, le visiteur possède des méthodes qui correspondent aux
méthodes paramètres. Pour qu'un objet algorithme fonctionne (i.e. sa méthode
run() soit opérationnelle) il faut qu'il agrège un objet visiteur qui
lui fournit les parties manquantes de son code. Cet objet peut être fourni par exemple
à la construction de l'algorithme. La figure 8.9 présente la classe
Algorithme qui manipule dans sa méthode run() un objet
visiteur implémentant l'interface de la classe Visiteur, cette
dernière fournit les méthodes paramètres opération1() et
opération2() nécessaires à l'algorithme.
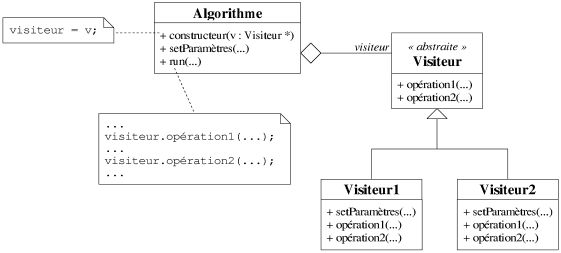 |
| Figure 8.9: Un exemple d'extension d'un algorithme par visiteur abstrait. |
L'exemple suivant montre la flexibilité apportée par la technique dans l'extension des algorithmes. Il est en effet possible de définir à l'exécution quel sera le visiteur d'un algorithme. Il faut noter que le visiteur peut avoir ses propres paramètres et qu'ils doivent être initialisés avant l'appel à l'algorithme principal.
Visiteur1 * v = new Visiteur1;
Algorithme * a = new Algorithme(v);
a.setParamètres(...);
v.setParamètres(...);
a.run(...);
Cependant, le défaut majeur, que l'on retrouvait déjà dans la
première approche, réside dans l'utilisation du mécanisme de virtualité
pour appeler les méthodes paramètres (e.g. les méthodes
opération1() et opération2() du visiteur).
| 8.2.2.3. Approche par concept de visiteur |
Pour éviter finalement le mécanisme de virtualité, il suffit de fournir le visiteur en paramètre et non pas en argument à l'algorithme, autrement dit ce dernier doit être un patron paramétré sur le type du visiteur qu'il manipule. Celui-ci doit alors simplement implémenter le concept de visiteur nécessaire à l'algorithme. La figure 8.10 illustre cette approche. L'exemple suivant montre que l'utilisation du visiteur est très similaire à l'approche précédente, la seule réelle différence à ce niveau étant que l'utilisateur n'a pas à créer explicitement de visiteur.
Algorithme<Visiteur1> * a = new Algorithme<Visiteur1>;
a.getVisiteur().setParamètres(...);
a.setParamètres(...);
a.run(...); Le mécanisme de virtualité étant écarté, la technique présentée ici ne présente aucune perte d'efficacité. En revanche elle ne permet aucune flexibilité dans la construction des algorithmes, la relation algorithme-visiteur est fixée à la compilation. Cette flexibilité est pourtant importante si l'on considère qu'une méthode (comme nous l'avons expliqué dans la section sur le patron stratégie) est capable d'analyser la structure d'un graphe, de déterminer et de fournir l'algorithme le mieux adapté grâce à un paramétrage dynamique de cet algorithme avec des visiteurs.
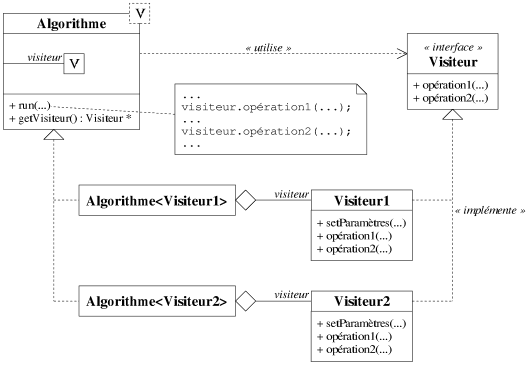 |
| Figure 8.10: Un exemple d'extension d'un algorithme par concept de visiteur. |
| 8.2.2.4. Conclusion |
Pour permettre une bonne généricité des algorithmes, il semble donc important d'appliquer le patron stratégie avec les modifications que nous avons proposées à la section 8.1, tout en le combinant avec l'approche par concept de visiteur pour permettre une extension efficace des algorithmes. En ce qui concerne les différentes bibliothèques proposées pour la recherche opérationnelle, il faut savoir que seule BGL propose réellement une extension des algorithmes, les autres fournissant plutôt des algorithmes dans un but unique.
L'approche employée dans cette bibliothèque est très proche, mais plus générique, que celle que nous avons retenue. Nous avons expliqué les raisons qui nous ont fait choisir une voie moins intéressante pour les réutilisateurs, mais plus réaliste pour les concepteurs. Il faut également noter que la bibliothèque STL emploie la notion de foncteur très similaire à la notion de concept de visiteur. D'autres approches sont proposées, notamment dans [Duretz-Lutz01] qui s'applique à proposer des versions génériques (i.e. avec des patrons de composant) d'un grand nombre de patrons de conception proposés dans [Gamma95].
| 8.2.3. Gestion de données additionnelles |
Il est très courant pour un algorithme d'avoir besoin d'affecter des données supplémentaires aux éléments des structures de données qu'il manipule. Par exemple un algorithme de résolution d'un problème de flot peut gérer un potentiel sur les noeuds du graphe, mais l'utilisateur ne doit pas connaître ce détail et se limiter aux données de flot. Nous discutons ici brièvement plusieurs manières de gérer ces données additionnelles.
La première approche consiste à stocker les données dans une structure à part du graphe. Un vecteur, par exemple, permet de conserver ces données dans le même ordre que les noeuds dans le graphe. L'accès aux données est immédiat, mais interdit toute modification du graphe qui perturberait l'ordre des noeuds. Il est alors possible d'utiliser un conteneur associatif pour stocker les données, par exemple un arbre binaire de recherche où l'identifiant d'un noeud joue le rôle d'une clé pour rechercher les données associées au noeud dans l'arbre. Cette approche autorise une modification structurelle du graphe, mais l'accès aux données est beaucoup plus lent (O(log n) opérations pour n noeuds dans le graphe).
Nous avons donc recherché une approche qui allie un accès efficace des données additionnelles à la flexibilité du graphe. Elle consiste à prévoir dans les classes des noeuds et des arcs un attribut qui référence pour chacun une zone mémoire que l'on appellera zone de travail. Cette zone n'est absolument pas gérée (ni même allouée) par la classe du graphe, mais par les algorithmes qui vont manipuler le graphe. Ainsi, lorsqu'un algorithme a besoin d'ajouter des données à un noeud, il lui suffit d'allouer ces données et de faire pointer l'attribut de la zone de travail dessus. A partir du noeud, l'accès aux données additionnelles est ainsi immédiat. Le code suivant illustre cette approche.
Graphe<Flot,Potentiel> * g = new Graphe<Flot,Rien>;
...
g.noeud(3).zoneTravail() = new Potentiel;
...
(Potentiel *)(g.noeud(3).zoneTravail()).potentiel = 2.5;
Cet exemple montre comment ajouter une donnée de la classe Potentiel (cf.
section 8.1) à un noeud, mais soulève un problème important qui est qu'un
downcast est nécessaire pour récupérer la donnée avec le bon
type. Nous avons discuté à la section 8.1 des défauts de cette
opération. La zone de travail doit néanmoins référencer n'importe quel
type de données. Les langages de programmation ont différentes manières de
représenter une référence sur un objet quelconque. Java propose la classe
Object dont toute classe hérite directement ou indirectement. C++ propose le
type void * qui représente une référence d'un type quelconque.
Un problème se pose également si plusieurs algorithmes ont besoin de la zone de travail, par exemple un algorithme de tension utilise la zone de travail mais fait appel à un algorithme de plus court chemin qui lui aussi a besoin de cette zone. Une approche consisterait, au début de chaque algorithme qui gère des données additionnelles, à sauvegarder les références de la zone de travail de chaque noeud par exemple avant de les remplacer par ses propres références. Il suffit alors de les restituer à la fin de la méthode, afin que l'algorithme appelant retrouve la zone de travail dans l'état où il l'a laissée.
Cela ne coûte qu'un nombre linéaire d'opérations en fonction du nombre de noeuds et reste négligeable pour la plupart des algorithmes. Cependant, il est possible d'obtenir une meilleure efficacité, en proposant simplement, au lieu d'une référence, une pile de références sur des zones de travail. Chaque algorithme qui gère des données additionnelles ajoute sa référence sur la pile, et celui qui est effectivement en cours d'exécution (on exclue ici une utilisation multithread) manipulera toujours la zone de travail au sommet de la pile.
| 8.3. CONCEPTION D'UNE BIBLIOTHEQUE REUTILISABLE |
Dans cette dernière section, nous proposons une brève présentation de l'avancement de notre bibliothèque, discutant de points certes pratiques, mais qui nous semblent très importants pour la réutilisabilité de la bibliothèque. Nous verrons qu'ils favorisent incontestablement la réutilisation de la bibliothèque par de tierces personnes, aussi bien pour un prototypage rapide que pour le développement d'un produit fini. Ces points concernent l'organisation même de la bibliothèque, mais également des aspects plus techniques comme la portabilité, dont nous expliquons qu'elle ne se limite pas simplement au portage sur un système d'exploitation. Cette présentation nous permettra de conclure sur les enjeux futurs de la bibliothèque, et de discuter de certaines corrections et évolutions à lui apporter.
| 8.3.1. Organisation de la bibliothèque |
| 8.3.1.1. Code source ou code compilé ? |
Notre manière de développer la bibliothèque repose sur une approche itérative. En effet, la première fois qu'un algorithme est créé, il est conçu principalement pour notre besoin immédiat, en pensant tout de même aux extensions les plus évidentes que l'on permet grâce à un paramétrage de l'algorithme (cf. les visiteurs). Mais il est très difficile (et trop coûteux en temps) d'envisager tous les usages d'un algorithme. C'est pourquoi nous procédons par raffinements successifs, ce qui explique qu'il nous semble indispensable de fournir le code source de la bibliothèque plutôt qu'une simple version compilée, afin qu'un réutilisateur puisse intervenir dans ce processus. Une autre raison pour fournir le code source est qu'un patron de composant se trouve entièrement dans l'interface, et que le seul moyen en C++ de l'instancier, pour les utilisateurs, est de posséder le code source associé.
Cependant, cette approche pose de nombreux problèmes. [Meyer97] considère que fournir le code source est une solution de facilité. Il justifie cela par le fait qu'il n'est pas nécessaire alors de considérer le portage de la bibliothèque sur de nombreux compilateurs différents, cette tâche incombant aux concepteurs de ces compilateurs en garantissant un standard. Mais en pratique, cela revient à laisser l'utilisateur se débrouiller avec le code source pour le compiler. Cette phase est extrêmement délicate si le concepteur n'a pas pris la peine de la préparer pour l'utilisateur. En outre, ce dernier ne réutilisera pas la bibliothèque s'il n'arrive pas à la compiler rapidement. Nous pensons donc qu'il est important d'assister l'utilisateur dans la phase de compilation et qu'il est par conséquent plus difficile de produire un code source compilable sur n'importe quel système plutôt que de le compiler uniquement sur quelques plateformes et d'en distribuer simplement une version compilée.
| 8.3.1.2. Vérification de la bibliothèque |
Il est impensable de fournir une bibliothèque réutilisable sans effectuer des tests certifiant d'une certaine fiabilité de ses composants. Il est peu réaliste de garantir une vérification absolue de la bibliothèque (e.g. [Balci98c]), mais une certaine rigueur et des séries de tests systématiques permettent de s'assurer du bon fonctionnement des composants lors de leur conception, et également que leur comportement est toujours fiable après une modification dans la bibliothèque. Pour cela nous avons opté pour trois techniques.
La première consiste à insérer des assertions dans le code source, c'est-à-dire des expressions qui doivent toujours être vraies au moment où elles sont testées dans le code. Si ce n'est pas le cas, une erreur est levée et l'utilisateur est informé du problème. Ces assertions sont naturellement activées uniquement lors de la phase de débogage de la bibliothèque, afin de ne pas altérer les performances des composants dans leur fonctionnement normal.
Une seconde technique consiste à fournir pour chaque module une procédure de test de ses composants générant une trace textuelle. A la première exécution, cette trace est vérifiée entièrement et est conservée pour servir de référence lors des futures exécutions de la procédure de test. Cela permet ainsi de s'assurer qu'une modification de la bibliothèque n'a pas entraîné d'erreur apparente. Cette technique permet également de vérifier que la bibliothèque est portable (par la comparaison sur plusieurs plateformes de la trace) et garantit aux utilisateurs le bon fonctionnement de la compilation qu'ils obtiennent de la bibliothèque.
La dernière technique, proche de la précédente, consiste à fournir pour certains modules une procédure de test automatique où les jeux d'essais sont générés aléatoirement et vérifiés automatiquement. Par exemple, deux algorithmes totalement différents pour un même problème peuvent confirmer mutuellement leurs résultats. L'intérêt de combiner ce type de test avec le précédent est évident: l'un est déterministe et garantit un certain bon fonctionnement par rapport aux prévisions du concepteur, alors que l'autre est aléatoire et peut donc soulever une anomalie à chaque exécution. La combinaison de ces deux techniques rejoint les conclusions fortes intéressantes apportées dans [Johnson02] concernant l'analyse par expérimentation d'algorithmes.
| 8.3.1.3. Documentation |
La documentation d'une bibliothèque joue un rôle indéniable dans sa réutilisabilité. Comme nous en avons parlé à la section 6.1, la documentation fait désormais partie intégrante du code source. Il existe cependant différentes manières de présenter la documentation d'une bibliothèque, en fonction de l'organisation des composants que l'on choisit de mettre en avant.
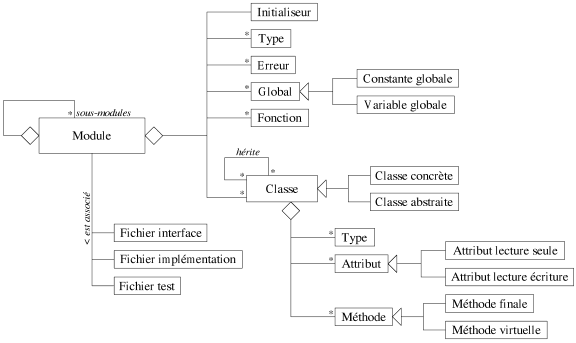 |
| Figure 8.11: Organisation de la bibliothèque. |
Cela dépend du langage et des concepts employés, mais aussi des outils utilisés pour générer la documentation qui ont tendance à favoriser une certaine vision. Pour notre bibliothèque, nous avons choisi une représentation qui reflète notre organisation en modules des composants. Nous proposons ici un schéma UML simplifié qui résume dans les grandes lignes cette organisation.
La figure 8.11 indique qu'un module est composé de trois fichiers sources: l'interface, l'implémentation et la procédure de test. Un module peut être décomposé en sous-modules. Chaque module contient des objets globaux (variables ou constants), des fonctions, des types, des erreurs (objets représentant les informations des erreurs que le module est susceptible de produire) et des classes. Chaque module contient également un initialiseur, objet chargé de gérer la création (avant la première utilisation du module) et la destruction (après la dernière utilisation du module) de ses objets globaux (nous revenons à la section suivante sur son utilité). Notre représentation ne met pas en avant la hiérarchie d'héritage comme la plupart des générateurs de documentation. La raison en est très simple: nous employons principalement les patrons et la composition à la place de l'héritage, contrairement à beaucoup de développements orientés objet.
| 8.3.2. Portabilité de la bibliothèque |
Comme il l'a été rapidement expliqué à la section 6.1, nous pensons que la portabilité d'une bibliothèque ne se limite pas seulement à sa capacité à être réutilisée sur différents systèmes d'exploitation. Il est en effet très courant dans le milieu industriel de vouloir faire interagir dans un environnement logiciel des composants provenants de plateformes (compilateurs, langages, systèmes d'exploitation...) différentes (cf. [Stroustrup95]). Afin de favoriser la réutilisabilité de notre bibliothèque, il est indispensable qu'elle puisse être intégrée dans de tels environnements. Nous avons donc tenté d'obtenir une indépendance du système d'exploitation, du compilateur et du système d'affichage, ce qui permet l'intégration de la bibliothèque dans une majorité d'environnements C++ existants. La compilation d'une version dynamique de la bibliothèque est également assurée, autorisant ainsi un chargement en temps réel de ses modules à l'exécution d'un programme, ce qui offre une possibilité d'interopérabilité avec d'autres langages que C++. Nous proposons dans ce sens un mécanisme permettant une forte interopérabilité avec Java, langage que nous avons longuement hésité à utiliser à la place de C++. Enfin le fonctionnement de la bibliothèque est garantit dans un environnement multithread. Nous discutons ici très brièvement de tous ces points, afin de justifier leur intérêt et d'éclairer le lecteur sur les approches employées et leurs éventuelles difficultés. Des détails pratiques sont disponibles dans [BacheletWeb].
| 8.3.2.1. Indépendance de l'environnement |
Le langage C++ n'est pas un langage totalement indépendant du système (système d'exploitation + compilateur) avec lequel il interagit. Un standard existe mais il reste malheureusement quelques ambiguïtés. La meilleure manière de rendre notre bibliothèque indépendante du système est de proposer une interface unique permettant à la bibliothèque de communiquer avec n'importe quel système. Le portage de la bibliothèque sur un nouveau système consistera donc simplement à implémenter l'interface. Pour simplifier cette étape, il est possible d'isoler dans quelques variables le peu de différences qu'il existe entre les implémentations de l'interface pour différents systèmes. Dans notre bibliothèque, un fichier source, dit de dépendance, très court, rassemble ces variables. Une partie de la figure 8.12 illustre le principe.
Pour tester cette approche, nous avons compilé notre bibliothèque sur
différents systèmes, chacun avec un fichier de dépendance spécifique.
Le réglage des variables de ce fichier est pour l'instant effectué manuellement, mais
nous envisageons de proposer un outil permettant la génération automatique du fichier
de dépendance grâce à des tests qu'il effecturait sur le système
d'exploitation et le compilateur. Un tel outil existe déjà dans le monde UNIX/Linux
avec la commande configure exécutée avant toute compilation d'un
logiciel. Il est en effet très délicat, pour un utilisateur n'ayant pas conçu
la bibliothèque, de régler le fichier de dépendance. En revanche, pour nous
les concepteurs, cette opération est assez immédiate. Cette approche offre donc tout
de même, dans son état actuel, un portage efficace (rapide et sûr) de la
bibliothèque.
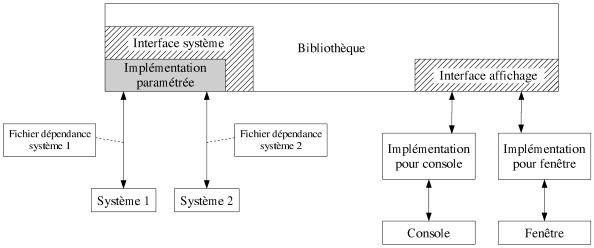 |
| Figure 8.12: Indépendance de la bibliothèque face à son environnement. |
Pour que la bibliothèque puisse coexister dans une application déjà existante, il faut également qu'elle soit indépendante du système d'affichage (texte, graphique ou autre). Un exemple simple est l'utilisation de la bibliothèque dans une interface graphique permettant de manipuler un graphe. Imaginons que l'on désire appeler un algorithme de la bibliothèque sur ce graphe. Il faut alors que la bibliothèque soit capable de dialoguer avec l'interface graphique, simplement pour informer l'utilisateur d'un mauvais fonctionnement ou de la progression d'un processus. Pour cela, il faut prévoir là aussi une interface pour que la bibliothèque communique avec tout système d'affichage (cf. figure 8.12). Ainsi, un utilisateur qui désire un affichage différent de celui fourni par défaut dans la bibliothèque devra implémenter l'interface, par exemple pour que les messages de la bibliothèque s'affichent dans une fenêtre plutôt que dans une console texte.
| 8.3.2.2. Bibliothèque dynamique |
Une bibliothèque est un rassemblement de composants logiciels. Sous sa forme compilée, une bibliothèque peut être statique ou dynamique. Si elle est statique, cela signifie qu'au moment de la compilation d'un programme (à l'édition de liens exactement), tous les composants nécessaires de la bibliothèque sont recopiés dans un fichier unique avec le reste du programme. Si la bibliothèque est dynamique (appelée souvent DLL, Dynamic Link Library), cela signifie qu'au moment de la compilation d'un programme, les composants nécessaires de la bibliothèque sont simplement référencés dans le fichier du programme (i.e. le nom du fichier et l'emplacement du composant dans celui-ci est noté), permettant ainsi en temps réel au programme d'aller chercher, quand il en a besoin, les composants dans les différents fichiers de la bibliothèque.
L'intérêt premier de cette forme dynamique est d'éviter une redondance de code, puisqu'un composant de la bibliothèque n'apparaît qu'une seule fois dans la mémoire de stockage, indépendamment du nombre de programmes qui l'utilisent. Mais l'intérêt secondaire qui nous intéresse ici est que la forme dynamique d'une bibliothèque renforce son interopérabilité avec un environnement C++ ou tout autre langage. En effet, il est possible en temps réel de consulter une bibliothèque dynamique et d'en sélectionner un composant. Ce protocole est en général standard pour un système d'exploitation donné, ce qui permet à un programme créé avec n'importe quel compilateur (C++ ou autre) d'accéder à certains composants de la bibliothèque (nous présentons par la suite un tel mécanisme avec Java).
Le fait que la bibliothèque soit dynamique ne pose aucun problème de conception. Excepté les quelques bugs liés à une sous-utilisation du mécanisme à l'heure actuelle par certains compilateurs, cela n'introduit au pire que quelques modifications dans le code source. Une catégorie de compilateurs (e.g. GNU GCC pour Linux) permet une compilation dynamique sans aucune modification du code source, c'est le compilateur qui se charge de tout. Cependant la plupart des compilateurs (e.g. sous Windows) nécessitent de rajouter dans le code source une instruction pour chaque composant logiciel que l'on désire exporter, i.e. être visible des programmes qui utilisent la bibliothèque. Il faut donc prévoir ce mécanisme dès l'écriture des premières lignes d'une bibliothèque.
L'initialiseur (vu à la section précédente) joue ici un rôle
très important, puisqu'il permet de manipuler un module comme une entité vraiment
indépendante. En effet, il gère la préparation d'un module avant son
utilisation et gère les dépendances d'utilisation qu'un module peut avoir avec
d'autres. Par exemple, si un module A utilise un module B, l'initialiseur de A
appelle automatiquement l'initialiseur de B. Ainsi, sous sa forme dynamique, un module de la
bibliothèque peut être préparé par son initialiseur en temps réel
et ses composants utilisés par un tiers sans aucun problème. Il faut savoir que cette
notion d'initialiseur n'existe pas en C++, sans ce mécanisme l'ordre d'initialisation des
objets globaux n'est pas contrôlé, ce qui peut causer d'énormes
problèmes (e.g. une allocation de mémoire alors que le mécanisme global de
gestion des allocations n'est pas initialisé). Dans un langage comme Java, cette notion
d'initialiseur est nativement implémentée, il s'agit du bloc static
{...} qu'une classe exécute à sa première utilisation.
| 8.3.2.3. Interopérabilité avec Java |
Nous avons longuement hésité pour le développement de la bibliothèque entre C++ et Java, et nous nous sommes rendus compte qu'il n'était pas réaliste d'employer Java principalement pour les structures de données et les algorithmes. Cependant, Java reste un langage incontournable et il serait dommage que notre bibliothèque ne puisse pas être réutilisée par les utilisateurs de ce langage. L'intérêt de Java est principalement sa portabilité qui est absolue dans le sens où les composants compilés avec ce langage sont exécutables sur tout environnement qui possède une machine virtuelle, composant logiciel simulant un ordinateur. A l'heure actuelle, tout ordinateur dignement équipé possède cette machine virtuelle Java (JVM, Java Virtual Machine).
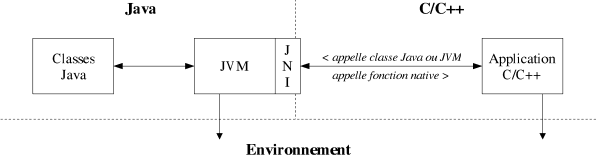 |
| Figure 8.13: Protocole Java Native Interface. |
Heureusement, il existe une interface simple et très complète qui permet aux composants Java (compilés dans le langage de la machine virtuelle) de communiquer avec des composants dits natifs, i.e. compilés dans le langage de la machine physique (et stockés dans une bibliothèque dynamique). Ce protocole d'échange, appelé JNI (Java Native Interface [Liang99]), permet à Java d'appeler une fonction C/C++ et à C/C++ de manipuler des objets, des classes, bref tout composant du monde Java (cf. figure 8.13).
Ce mécanisme JNI offre peu de possibilités du côté Java, simplement l'appel de fonctions C/C++. Si l'on désire par exemple exécuter un algorithme C++ sur un graphe Java, il faut concevoir une fonction C++, appelable de Java, qui traduit le graphe Java en un graphe C++, exécute l'algorithme C++ et traduit finalement le résultat C++ en un résultat Java. Bien que très simple et très complet, JNI est difficilement utilisable directement. La manipulation simple d'un composant Java nécessite une dixaine de lignes de code C/C++ et la détection d'éventuelles erreurs, ce qui freine considérablement l'utilisation de ce mécanisme.
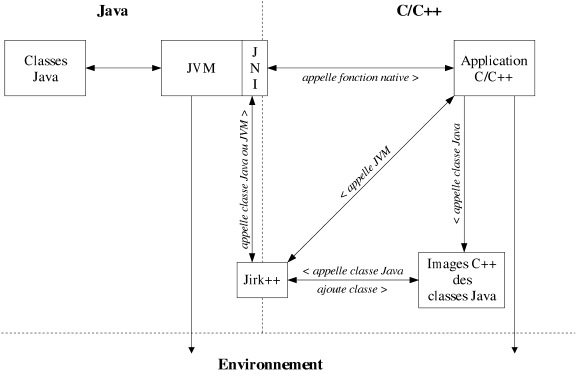 |
| Figure 8.14: Mécanisme Jirk++. |
Afin de permettre une réelle interaction entre notre bibliothèque et Java, nous avons proposé une modélisation C++ qui permet de manipuler directement et très simplement un composant Java en C++. Chaque classe Java possède une représentation C++, et c'est cette classe qui est appelée en C++, elle délègue ensuite toute exécution à son équivalent Java (cf. figure 8.14). De plus amples détails sur ce mécanisme, appelé Jirk++, sont disponibles dans [BacheletWeb]. Cette interopérabilité suscite quelques intérêts puisque la bibliothèque GTL propose une version, GTL Java, qui utilise JNI pour permettre de manipuler ses composants en Java. Il existe également des outils commerciaux plus généralistes, équivalents à Jirk++, qui facilitent le développement de logiciels à fort couplage C++/Java (e.g. JunC++ion [CodemeshWeb], JNI Assistant [KeyTechnologyWeb]).
| 8.3.2.4. Multithreading |
La portabilité passe également par la possibilité d'utiliser la bibliothèque dans un environnement où plusieurs tâches, et donc des composants de la bibliothèque, peuvent être utilisées en parallèle. Nous nous intéressons ici aux environnements multithread où un programme peut être séparé en plusieurs exécutions parallèles, les threads, partageant les ressources (variables globales, fonctions, classes...) du programme. Cette fonctionnalité nous a semblé importante pour différentes raisons. Tout d'abord, Java exploite pleinement le multithreading, il faut donc s'attendre de la part des réutilisateurs Java à utiliser un composant de la bibliothèque en parallèle. Ensuite, en recherche opérationnelle la rapidité est un facteur majeur, il est donc souvent intéressant de pouvoir paralléliser des calculs sur des machines multiprocesseurs. La bibliothèque doit donc être portable et réutilisable dans un tel environnement. Ce portage n'entraîne pas de problèmes compliqués (cf. [WagnerWeb]), mais une certaine discipline de conception: protéger les ressources globales dynamiques (i.e. dont l'état peut changer au cours du programme) contre une manipulation simultanée par des threads différents. A l'heure actuelle, bien que la bibliothèque soit conçue pour le multithreading, tous les compilateurs ne l'implémentent pas pleinement.
| 8.3.3. Gestion des erreurs |
Jusqu'à présent, nous avons totalement éludé les problèmes liés à la gestion des erreurs. Il est en effet possible qu'un utilisateur manipule mal un composant lors de l'exécution d'un programme. Lorsqu'une telle erreur se produit, il est possible de la gérer au niveau du composant, mais la plupart du temps, il est souhaitable d'informer l'utilisateur du mauvais fonctionnement. Cela pause un réel problème de portabilité: comment informer l'utilisateur ? Faut-il transmettre l'erreur au système d'affichage, faut-il émettre un son... Cela dépend naturellement de l'environnement logiciel avec lequel la bibliothèque interagit.
L'idéal serait que la gestion de l'erreur incombe à l'environnement logiciel même. Pour cela le mécanisme d'exception existe. Lorsqu'une erreur survient, soit la fonction (ou la méthode) où elle apparaît la gère, soit l'erreur est jetée. On l'appelle alors une exception, et cela signifie que la fonction courante est arrêtée et que l'erreur est transmise au composant appelant. A son tour, ce dernier va décider de traiter l'erreur ou de la jeter à nouveau au composant qui l'a appelée. L'exception peut ainsi remonter jusqu'au premier composant appelant qui lui est alors obligé au final de la gérer.
Ce mécanisme est très intéressant d'un point de vue réutilisabilité, puisqu'il renforce le découplage entre un composant et ceux qui l'utilisent. La bibliothèque peut tout à fait détecter des erreurs, les gérer quand cela est possible et sinon les jeter. Le logiciel utilisateur n'aura qu'à se charger au final de la gestion des erreurs restantes et d'informer l'utilisateur s'il le souhaite. Ce mécanisme d'exception n'est pas toujours très utilisé car son fonctionnement est assez difficile à implémenter, tous les compilateurs jusqu'à récemment ne le géraient pas parfaitement. Ce mécanisme entraîne également un léger ralentissement du programme (cf. [ORiordan02]) puisque des informations doivent être accumulées en temps réel afin de permettre une remontée sans problème dans l'empilement des appels de fonction.
En revanche, l'utilisation des exceptions est très simple et favorise indéniablement la réutilisabilité. Elle offre une meilleure indépendance des composants et contribue à leur fiabilité: le compilateur se charge d'ajouter le code nécessaire pour stopper une fonction, opération qu'il effectue plus sûrement que tout programmeur; le concepteur est également déchargé d'une partie de sa tâche, il doit détecter les erreurs, mais il n'est pas obligé de toutes les gérer (il aura donc tendance à en détecter plus).
| 8.3.4. Implémentation de la notion de concept |
Nous avons vu au chapitre 7 un défaut très important en pratique des patrons. Un mauvais paramétrage d'un patron entraîne des erreurs dans son implémentation et non pas dans celle du réutilisateur. Ce défaut est lié au langage utilisé, en l'occurrence C++, et il serait intéressant de mettre en place un mécanisme qui permette à l'utilisateur de mieux comprendre son erreur. Dans cet objectif, les travaux [McNamara00] et [Siek00] proposent une manière d'introduire explicitement la notion de concept en C++ et de permettre alors de vérifier avant l'instanciation d'un patron que ses paramètres implémentent bien le ou les concepts requis. Les messages d'erreur apparaissent ainsi plus explicites et lient la tentative d'instanciation d'un patron de l'utilisateur aux concepts requis par ce même patron. Nous étudions actuellement la possibilité d'implémenter un tel mécanisme dans notre bibliothèque.
| 8.3.5. Vers un environnement de développement |
Nous avons présenté dans cette dernière section l'état d'avancement de notre bibliothèque et les modifications éventuelles assez immédiates que nous pourrions lui apporter. Nous expliquons maintenant très sommairement le rôle que nous souhaitons donner à cette bibliothèque dans une ambition à long terme de fournir un environnement de développement pour les problèmes de graphes, comme il en existe déjà dans de nombreux domaines, notamment la conception de logiciels et la simulation. Très brièvement nous présentons les différents outils que nous imaginons dans cet environnement résumé par la figure 8.15.
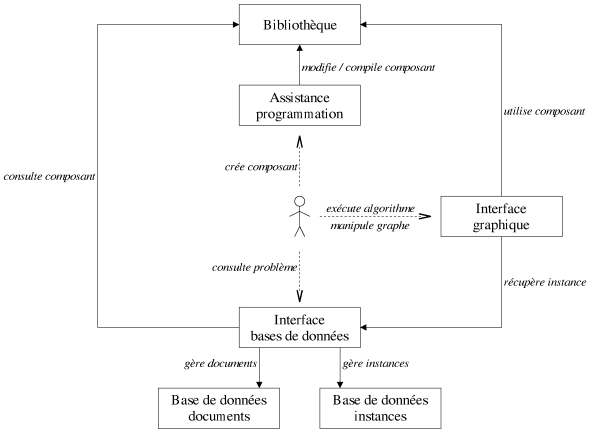 |
| Figure 8.15: Environnement de développement pour les problèmes de graphes. |
La création d'une bibliothèque suppose une organisation, cela signifie que si l'on veut rajouter un composant, il ne suffit pas d'écrire son implémentation, il faut également l'insérer dans la bibliothèque avec des manipulations qui permettent une interaction avec les autres composants. En fonction du type de bibliothèque et des objectifs qui lui sont assignés, la phase d'intégration est plus ou moins évidente. Dans le cas de notre bibliothèque, nous proposons des squelettes de fichiers qu'un réutilisateur peut compléter pour intégrer un composant dans la bibliothèque. Dans le but d'abstraire ces mécanismes internes totalement inutiles pour un réutilisateur, il serait intéressant de lui fournir une interface, un éditeur, où il n'y ait qu'à écrire le composant, et un mécanisme caché se chargerait d'intégrer automatiquement le composant dans la bibliothèque en garantissant sa portabilité. Cette interface, couplée à la documentation, pourrait servir à la recherche et à l'accès rapide à un composant.
Les graphes ont souvent une représentation graphique, il semble intéressant pour la vérification, le débogage et, d'un point de vue pédagogique, l'apprentissage d'algorithmes de posséder un outil permettant de visualiser un graphe et les données qu'il porte. Cette interface est également importante pour la création de graphes. Nous pensons que manipuler une représentation graphique des graphes facilite énormément la phase de développement et de vérification d'un algorithme. Comme cela a été le cas en simulation, le fait de posséder une représentation visuelle du problème permet à l'humain de détecter des incohérences qu'il ne pourrait pas détecter par des traces textuelles (cf. [Hill96], [Balci98c]). Nous travaillons actuellement au développement d'une interface graphique pour la représentation et l'édition de graphes en Java (cf. [Masson02]). Cet outil pourra être interfacé avec tout type de composant logiciel Java, C ou C++, et permettra donc d'appliquer des algorithmes provenant de ces différents langages sur les graphes manipulés dans l'interface et d'en visualiser la progression (sous une forme textuelle ou directement sur le graphe manipulé). Cette interface à elle seule offrira déjà un progrès important dans la conception d'algorithmes pour les problèmes de graphes. Cet outil n'est en aucune façon dédié spécifiquement à notre bibliothèque, mais grâce au mécanisme d'interaction Jirk++ qu'elle propose avec Java, elle est favorisée pour utiliser cet outil.
A ces interfaces de visualisation et d'assistance, nous pensons également associer des bases de données permettant de gérer et de cataloguer les problèmes de graphes. Pour un problème donné, il est important de pouvoir consulter et ajouter des références bibliographiques, de tester et de créer des instances de ces problèmes (stockage d'instances avec leur solution exacte ou la meilleure solution connue, algorithmes pour générer de nouvelles instances...), de réutiliser et de concevoir des méthodes de résolution... L'environnement que nous envisageons a donc pour but d'assister l'utilisateur dans toute la phase d'implémentation de sa méthode, en passant par l'intégration de la méthode à la bibliothèque, son débogage, la génération d'instances et sa vérification. Nous espérons que cela permette à terme (i.e. une fois la bibliothèque suffisamment garnie) le prototypage rapide et sûr de nouvelles méthodes de résolution.
| CONCLUSION |
Les premiers chapitres ont consisté à justifier l'intérêt de la réutilisabilité dans la conception d'une bibliothèque de composants de recherche opérationnelle, et à démontrer que l'approche orientée objet n'est pas forcément un facteur pénalisant pour l'efficacité des composants logiciels, mais permet au contraire, en utilisant judicieusement les possibilités du paradigme objet, une généricité, une facilité d'utilisation et une portabilité des composants.
Dans le dernier chapitre, nous avons tenté d'illustrer ces propos en discutant de choix de conception rencontrés lors de l'élaboration de notre bibliothèque. Nous n'avons présenté que quelques points, insistant principalement sur les structures de données et les algorithmes qui sont les composants majeurs d'une application de recherche opérationnelle. Nous avons montré comment les rendre génériques, c'est-à-dire indépendants et extensibles, avec une perte d'efficacité tout à fait négligeable. Les approches que nous avons retenues ne sont pas toujours les meilleures d'un point de vue conceptuel (notamment notre choix d'une abstraction modérée des structures de données contrairement à celle proposée par la bibliothèque BGL), mais il a fallu prendre en considération certaines difficultés techniques qui nous ont conduit à un compromis qui satisfait plus les concepteurs/réutilisateurs que les utilisateurs finaux. Nous précisons simplement que les approches que nous avons écartées pour ces raisons n'ont pas été abandonnées, et que la bibliothèque a été conçue de manière à permettre d'y revenir ultérieurement. Notamment, le fait que nos algorithmes ne soient pas indépendants totalement des structures de données qu'ils traitent peut être corrigé aisément, avec seulement la modification des signatures des composants. Les structures sont suffisamment isolées à l'aide d'itérateurs qu'il est simple de les abstraire totalement. Nous attendons maintenant dans ce cas une évolution des compilateurs C++ dans la gestion des patrons de composant.
Pour conclure sur ces aspects de conception, nous citerons simplement quelques exemples de notre bibliothèque où nous avons appliqué les concepts d'algorithmes génériques retenus ici. Ceci n'est qu'un bref aperçu du potentiel de cette approche.
- Le premier exemple concerne le tri topologique (cf. annexe) qui consiste à numéroter les noeuds d'un graphe dans l'ordre de parcours à partir de la source. Un visiteur pour cet algorithme consiste à fournir une méthode qui indique si un arc peut être utilisé ou non dans le parcours. Cela permet, en revenant à la discussion du chapitre 4 sur l'algorithme de mise à l'échelle du dual, d'appliquer un tri topologique sur le graphe résiduel sans avoir physiquement à créer ce graphe.
- Un second exemple assez évident dans notre étude des problèmes de tension est l'algorithme de Minty qui se base sur la coloration (4 couleurs au total) des arcs pour rechercher certains cycles ou cocycles (cf. chapitre 2). Le visiteur ici consiste à fournir une méthode qui indique la couleur d'un arc. Ainsi, en fournissant différents visiteurs mais un seul algorithme, il est possible de produire des algorithmes pour trouver des circuits simples, des cycles avec flot augmentant, des cocycles avec tension augmentante...
- Notre troisième exemple concerne l'un des algorithmes majeurs de ce mémoire, la mise à conformité. Plus précisément la procédure qui améliore la conformité d'un arc. Elle est employée avec différents types de coût: coût linéaire, coût linéaire par morceaux, coût convexe... L'idée ici est de paramétrer la fonction avec un visiteur qui fournit toutes les informations concernant la courbe de conformité d'un arc. Ainsi, la procédure est toujours la même, mais pour savoir si une augmentation par exemple est possible sur un arc, elle interroge le visiteur de conformité. Le corps de la fonction n'a été codé qu'une seule fois et utilisé dans des situations très différentes.
Nous avons finalement présenté notre bibliothèque qui est loin d'être aboutie, mais qui a atteint à notre avis un stade où sa réutilisabilité apporte des gains en temps de développement pour la conception rapide de prototypes de recherche. Nous espérons très rapidement prouver son utilité dans l'élaboration de produits finis, puisque des efforts de conception (facilité d'utilisation des composants, possibilité d'intégration dans divers environnements...) ont été fournis dans ce but, notamment avec l'avancée du développement d'une interface graphique en Java permettant de manipuler visuellement des graphes et de leur appliquer de manière très intuitive différents algorithmes qui pourraient éventuellement provenir de notre bibliothèque.
Afin de rester objectif, il faut tout de même souligner le manque de lisibilité immédiate de notre bibliothèque, elle nécessite en effet un certain effort d'apprentissage de la part de l'utilisateur. Cette difficulté est liée à une syntaxe chargée en C++ pour décrire des patrons de composant. Elle est dûe également au fait qu'un grand nombre de composants sont organisés dans la bibliothèque et que l'ajout d'un composant doit respecter certaines règles pour que tout se passe bien. Nous pensons que cette étape peut être améliorée par une interface (visuelle ou un nouveau langage) entre l'utilisateur et le code source C++.
En conclusion, nous espérons avoir convaincu, à travers nos discussions dans cette dernière partie, de l'intérêt de concevoir une bibliothèque de composants réutilisables pour la recherche opérationnelle, et plus important de la faisabilité de cette ambition, à condition d'y consacrer suffisamment de ressources humaines. Notre bibliothèque est une tentative dans ce projet dont la réussite dépend énormément des contributions de chacun, qui permettront un enrichissement progressif par l'apport de nouveaux composants logiciels. Enfin, il nous semble important à terme d'envisager un environnement complet d'assistance au développement d'outils pour les problèmes de graphes, dans le but de faciliter et d'accélérer le déploiement de nouvelles méthodes d'optimisation.
|