 |
6. LA REUTILISABILITE LOGICIELLE |
| Avant-propos |
La recherche opérationnelle est une discipline où divers outils théoriques sont utilisés pour résoudre de nombreux problèmes pratiques. Malheureusement, la manière dont les experts de ce domaine apportent leurs réponses ne facilite pas toujours une exploitation ultérieure de leurs travaux, aussi bien par des néophytes que par des personnes averties.
En effet, la recherche opérationnelle répond généralement à un problème par une méthode de résolution dont la diffusion se fait principalement par une publication dans une revue scientifique où le principal intérêt, à juste titre, est la théorie qui a permis d'élaborer l'algorithme. La méthode est alors présentée sous une forme très abstraite et s'adresse donc à un public averti. Le degré de réutilisabilité d'un algorithme sous cette forme est alors très faible. Cela suppose de la part du réutilisateur une très grande compétence des concepts fondateurs de l'algorithme pour pouvoir implémenter à son tour la méthode. La présentation de l'algorithme est souvent très détaillée sur le plan théorique, mais est trop laxiste sur l'implémentation dont l'expérience de l'auteur ne peut alors pas profiter au réutilisateur.
A l'opposé, pour un utilisateur non expert en recherche opérationnelle, la tendance est généralement de lui développer un logiciel qui implémente la méthode de résolution élaborée avec une interface suffisante. Le programme résout alors un problème précis et satisfait le plus souvent l'utilisateur final qui n'a aucune connaissance du fonctionnement de l'algorithme implémenté, il sait juste qu'en fournissant certaines données il obtient un certain résultat. Le degré de réutilisabilité de la méthode sous cette forme est là aussi très faible: le programme est certainement très simple d'utilisation, mais il est souvent très difficile, voire impossible, de l'adapter pour résoudre un autre type de problème sans connaître précisément à la fois l'aspect théorique et l'implémentation de la méthode.
En écartant la publication qui est indispensable pour la communauté scientifique, une manière idéale de diffuser une méthode de résolution serait un moyen qui conviendrait à la fois aux personnes qui désirent un produit fini et aux personnes qui veulent réutiliser un algorithme sans en connaître les détails et surtout les fondements théoriques difficiles à appréhender, et dont l'acquisition peut être perçue comme une perte de temps et donc d'argent. Les composants logiciels peuvent répondre à ce besoin. Il est possible de fournir un algorithme sous une forme relativement simple, à partir de laquelle un produit fini peut rapidement être développé, et également sous une forme suffisamment souple, pour qu'un utilisateur plus averti, mais non nécessairement expert, puisse réutiliser l'algorithme dans un contexte différent de son utilisation première (e.g. un algorithme de plus court chemin peut être adapté pour rechercher une tension compatible dans un graphe, cf. algorithme 3.7).
Quelques bibliothèques de composants réutilisables existent déjà, nous en parlerons plus en détail par la suite, mais elles n'ont pas la célébrité que peuvent avoir certaines bibliothèques équivalentes en génie logiciel pour la conception d'interfaces (e.g. Borland C++ Builder [BorlandWeb], Microsoft Visual C++ [MicrosoftWeb]) ou en simulation à événements discrets (e.g. VSE [OrcaWeb]). Une raison peut être que la souplesse de l'implémentation des méthodes est généralement trop faible, l'utilisateur se trouve rapidement obligé de réécrire complètement les algorithmes. Une autre raison peut être que ces bibliothèques sont souvent développées avec des langages orientés objet et que des composants réellement souples pêchent par un excès d'utilisation des concepts objets dans leur conception, ce qui freine toute personne non experte en programmation orientée objet à réutiliser, voire adapter, un composant à ses besoins. Cela peut également conduire à une utilisation excessive des ressources mémoire et processeur.
Au cours de notre étude, nous avons dû implémenter divers algorithmes et structures de données. Depuis le départ, notre politique a été de fournir des composants logiciels réutilisables. Cela nous a conduit progressivement au développement d'une bibliothèque portable (i.e. elle peut aisément être intégrée dans un programme existant et peut donc servir au développement d'un produit fini) et avec, nous l'espérons, des composants suffisamment réutilisables (mais pas trop) qui permettent un développement rapide de prototypes. Notre objectif à très long terme étant de fournir une plateforme de développement complète pour la recherche opérationnelle (plus précisément pour les problèmes d'optimisation dans les graphes) comportant: des composants réutilisables, une représentation visuelle des graphes, une génération et une gestion des instances de problèmes et des campagnes de tests numériques, une documentation des problèmes et des algorithmes...
Le but de la dernière partie de ce document est donc de justifier la nécessité de développer des bibliothèques de composants réutilisables pour la recherche opérationnelle, et d'éclairer les raisons qui font que les bibliothèques existantes sont si peu utilisées, en discutant notamment de certaines idées reçues sur la programmation orientée objet qui freinent très certainement l'utilisation et le développement de composants réutilisables. Dans cette présentation nous nous appuyons sur notre expérience, ne prétendant aucunement que notre bibliothèque soit meilleure qu'une autre. Nous pensons simplement que chacune a ses défauts, ses avantages et que par conséquent, chacune est adaptée à un certain type d'utilisation. Notre discussion portera donc sur les différents choix de conception possibles en fonction des besoins des réutilisateurs.
Dans un premier chapitre, nous discutons de la réutilisabilité logicielle, de manière générale mais aussi par rapport à la recherche opérationnelle, et exposons les différents enjeux qu'elle suscite. Pour les personnes peu familières avec la programmation orientée objet, le second chapitre introduit quelques concepts du paradigme objet et explique leur impact sur la réutilisabilité, ce qui nous permettra de mieux comprendre pourquoi la recherche opérationnelle ne trouve pas un intérêt pour la programmation orientée objet aussi important que d'autres disciplines. Le troisième chapitre sera consacré à des patrons de conception (i.e. design patterns) qui formalisent la manière d'implémenter des structures de données et des algorithmes génériques pour la recherche opérationnelle, nous discuterons de leur pertinence en fonction de différents objectifs de réutilisabilité. Enfin, nous terminerons ce chapitre par une brève présentation de notre bibliothèque, nous permettant ainsi d'exposer nos réflexions, notre état d'avancement et notre ambition de développer une plateforme de développement pour la recherche opérationnelle.
| INTRODUCTION |
La volonté de réutiliser ce qui a déjà été créé a toujours existée. Dans tous les domaines, les scientifiques profitent du travail de leurs prédécesseurs pour progresser. Bien évidemment, l'informatique n'échappe pas à cette règle, mais du souhait à la réalisation il y a un réel décalage. Dans ce chapitre, nous allons avant tout parler de réutilisabilité au sens large et montrer que ce terme est très subjectif et qu'il dépend du réutilisateur. Il est reconnu qu'à tous les niveaux d'abstraction ces concepts existent, mais en recherche opérationnelle, c'est plus particulièrement dans les niveaux les plus concrets, là où l'aspect logiciel intervient, qu'ils sont le moins présents. Nous nous concentrerons alors sur la phase de conception logicielle.
Cette étape est guidée par le génie logiciel qui est une discipline qui apporte des méthodologies, des outils, des concepts... pour développer des logiciels de qualité. Cependant, il est notable que ce domaine se penche plutôt sur une certaine catégorie de logiciels où la problématique est la quantité et la variété des éléments qui interagissent dans le logiciel (e.g. gestion de systèmes d'information, outils de bureautique, interfaces utilisateur, simulation à événements discrets...).
La recherche opérationnelle, que nous limiterons dans la suite du document à l'étude de problèmes dans les graphes, n'est pas confrontée la plupart du temps à ce type de difficulté. En effet, comme cette discipline tente de répondre le plus souvent de manière théorique à un problème, sa formulation est naturellement relativement simple (même si elle a pu être très compliquée à obtenir, sa forme finale est souvent très synthétique). Ainsi, le génie logiciel qui apporte surtout des réponses quant à la modélisation d'un système, n'éclaire pas beaucoup sur la manière de concevoir et d'implémenter un algorithme (pour nous une méthode de résolution d'un problème dans les graphes) et encore moins sur la manière de les rendre réutilisables et structurés dans une bibliothèque.
L'un des buts de ce chapitre est justement d'expliquer la différence qu'il peut exister entre la conception d'un logiciel au sens classique du génie logiciel et la conception d'un logiciel de recherche opérationnelle, en l'occurrence une bibliothèque de composants logiciels réutilisables. Dans un premier temps, nous discutons des principaux critères de qualité d'un logiciel, des problématiques et des enjeux qu'ils entraînent dans sa conception, et le rôle important tenu par la réutilisabilité. Nous proposons ensuite une rapide description des différentes phases de conception d'un logiciel, qui traduisent en fait différents niveaux d'abstraction du logiciel et où la réutilisabilité est présente par divers moyens. Nous terminons avec un historique de l'évolution des langages de programmation qui a été guidée principalement par un besoin de réutilisabilité, et qui a conduit naturellement à l'approche objet dont nous présentons les principaux concepts et leurs apports à la réutilisabilité au chapitre suivant.
| 6.1. QUALITE LOGICIELLE |
Dans ce document, nous appelons composant logiciel tout élément logiciel: fonction / procédure, structure / enregistrement, variable, classe / type abstrait, objet, méthode, attribut, module, bibliothèque, programme... Nous rappelons les principaux critères reconnus pour juger de la qualité d'un composant logiciel dont nous empruntons les définitions à [Meyer97] et [Booch87], et nous discutons de leur rôle dans le développement de composants logiciels de recherche opérationnelle.
| 6.1.1. Fiabilité: validité et robustesse |
La validité est la capacité d'un composant logiciel à effectuer les tâches pour lesquelles il a été défini. En recherche opérationnelle, une partie de ce critère est garanti par les preuves que l'on peut apporter sur le bon fonctionnement d'un algorithme. Il s'agit ensuite de vérifier que l'implémentation correspond aux spécifications de l'algorithme formel. Cette tâche est relativement simple en comparaison avec le génie logiciel ou la simulation où souvent la complexité des modèles (notamment le nombre de composants et la diversité des interactions qu'il existe entre eux) rend toute vérification impossible. On doit alors se reposer sur des méthodes, des outils de vérification, de validation et d'accréditation (e.g. [Balci98c]) qui permettent d'apporter une certaine confiance (appelée accréditation) sur la validité d'un composant logiciel.
La robustesse est la capacité d'un composant logiciel à réagir de manière appropriée à des conditions anormales. Ce critère est déjà beaucoup plus difficile à atteindre, il suppose de la part de l'auteur une clairvoyance rare pour imaginer toutes les situations anormales possibles, même si un peu de rigueur dans le développement du logiciel permet d'en détecter la plupart. En outre, comment réagir à de telles situations, quelle est la réaction appropriée ? La réponse peut se trouver dans les spécifications du composant logiciel, dans ce cas la situation n'est pas anormale et l'on revient à la notion d'exactitude. En revanche, si les spécifications n'ont pas prévu la situation, alors c'est le bon sens de l'auteur qui permettra de trouver une réaction appropriée. Une façon de fournir toujours une réponse à peu près appropriée consiste à traiter toute situation anormale comme une erreur, une exception (cf. chapitre 8) est alors levée et la lourde tâche de gérer la situation anormale est alors déléguée au composant logiciel appelant (celui qui a demandé au composant subissant la situation anormale d'agir).
Les notions de validité et de robustesse étant vraiment très proches, elles sont couramment regroupées sous le terme fiabilité qui est alors la capacité d'un composant logiciel à réagir selon l'attente du concepteur.
| 6.1.2. Extensibilité et maintenabilité |
L'extensibilité d'après [Meyer97] (ou la modifiabilité d'après [Booch87]) est la capacité d'un composant logiciel à être adapté aux changements de spécifications ou à des corrections d'erreurs. Il est naturel au cours de la vie d'un composant logiciel que ses spécifications changent, tout simplement à cause d'erreurs détectées dans son fonctionnement, mais très souvent aussi en raison de changements des besoins des utilisateurs du composant au cours du temps. Ce critère est d'autant plus difficile à atteindre que le nombre de composants logiciels dans le programme ou la bibliothèque est important. Il faut créer des composants les plus indépendants possible les uns des autres, afin qu'une modification locale à l'un des composants se répercute le moins possible aux autres composants. Cependant, cette indépendance se fait généralement au détriment de la vitesse d'exécution et parfois d'une simplicité de conception. [Booch91] recommande de structurer les composants en modules (cf. section 6.4) où les composants qui participent à une même fonctionnalité globale sont regroupés.
Il faut noter que cette définition de l'extensibilité est très proche de ce que communément on appelle la maintenabilité. Cette notion correspond plutôt au développement d'un programme où l'utilisation des composants se limite au programme, il est alors logique dans cette simple optique que tout changement de spécification implique des modifications dans les composants. Lorsque l'on développe une bibliothèque, l'utilisation des composants n'est pas toujours limitée à la bibliothèque. De nouveaux besoins peuvent en effet entraîner la modification même de composants, mais le plus souvent elle consiste en une extension (i.e. modification de la fonctionnalité) de composants: les anciens ne sont pas modifiés, mais exploités pour créer des composants répondant aux nouveaux besoins. Le terme extensibilité dans le développement d'une bibliothèque correspond donc plutôt (e.g. [Berthouzoz95]) à la capacité d'un composant logiciel à pouvoir être étendu sans être modifié.
| 6.1.3. Homogénéité: intelligibilité et compatibilité |
L'intelligibilité est la capacité d'un composant logiciel à être compréhensible. Aussi bien au niveau le plus concret avec un code source le plus clair possible (e.g. nom représentatif et lisible pour une variable, organisation du corps d'une fonction afin de mettre en évidence sa logique algorithmique...), mais également à un niveau plus conceptuel avec une structuration des composants logiciels. Elle nécessite généralement pour un développement à grande échelle d'établir un guide de style, des règles d'écriture et d'organisation des composants, permettant d'homogénéiser la conception des différentes parties d'un logiciel. La documentation notamment participe pleinement à l'intelligibilité d'un composant. C'est la raison pour laquelle à l'heure actuelle elle est considérée comme partie intégrante de la phase d'implémentation (cf. [daSilva96]): lors de l'écriture du code source, des commentaires suivant un guide de style particulier peuvent être imposés pour permettre à des outils d'extraire automatiquement une documentation lisible, structurée et navigable des composants logiciels (e.g. Javadoc [SunWeb2], Doxygen [vanHeeschWeb]).
La notion d'intelligibilité est à rapprocher très fortement de la notion de compatibilité qui est la capacité de composants logiciels à interagir les uns avec les autres. En effet, toute tentative d'homogénéisation, favorable à l'intelligibilité, va tout naturellement contribuer à développer des composants compatibles. Si l'on cherche la compatibilité avec d'autres logiciels, il faudra alors utiliser des standards: formats de fichier (e.g. XML [W3CWeb2]), types de donnée, protocoles de communication inter-programme (e.g. Corba [OMGWeb2])...
En raison des moyens communs employés pour atteindre ces deux critères, nous préférerons nous pencher sur l'homogénéité que nous définissons comme la capacité de composants logiciels à posséder une même logique simple dans leur conception. Nous pensons que si le critère d'homogénéité est atteint par des composants logiciels, alors leur intelligibilité et leur compatibilité sont quasiment garanties.
| 6.1.4. Portabilité |
La portabilité est la capacité d'un composant logiciel à être transféré d'un environnement à un autre. Le souci premier de la portabilité est avant tout de parvenir à transférer un composant logiciel d'une machine à une autre, d'un système d'exploitation à un autre. Cette problématique s'estompe à mesure que les années passent. En effet, l'enjeu dans l'industrie des logiciels est telle que les compilateurs et les interpréteurs deviennent de plus en plus standards, et les échanges avec le système d'exploitation sont pour la plupart maintenant uniformisés (e.g. la norme POSIX pour la gestion des fichiers, les représentations numériques, les threads... [JTC1Web]; le système graphique X Window [XOrgWeb]; le langage Java avec sa machine virtuelle [SunWeb1]).
Dans le cadre du développement d'un programme, la portabilité s'arrête ici. Par contre, dans la conception d'une bibliothèque de composants, il faut se soucier également de pouvoir l'intégrer dans un logiciel existant, ce qui complique sérieusement la conception: la bibliothèque peut être liée statiquement à un programme (i.e. au moment de sa compilation), dynamiquement (i.e. au moment de l'exécution du programme), utilisée dans un programme avec des threads concurrents (i.e. utilisant au même moment un même composant de la bibliothèque), avoir besoin de communiquer avec l'utilisateur (e.g. indice de progression d'un traitement long ou avertissement d'un problème)... Certains de ces problèmes sont discutés plus en détail dans le chapitre 8.
| 6.1.5. Efficacité |
L'efficacité est la capacité d'un composant logiciel à utiliser le moins de ressources possibles pour effectuer sa tâche. Ce critère est généralement source de compromis. Tout d'abord, entre le taux d'occupation mémoire et le taux d'occupation processeur, puisque souvent une baisse de l'un impose une augmentation de l'autre. Ensuite, les critères de qualité présentés précédemment ne sont pas toujours favorables à l'efficacité: la fiabilité entraîne plus de tests dans les traitements, l'extensibilité une généralisation du composant et donc des opérations supplémentaires, et l'homogénéité et la portabilité des contraintes de conception.
En général, on constate deux types d'attitude vis-à-vis de l'efficacité. Tout d'abord, il y a ceux qui cherchent à tout prix à obtenir un code très optimisé, ce qui nécessite beaucoup de temps et ne favorise en aucun cas la portabilité et l'extensibilité, voire nuit à la fiabilité. D'un autre côté, il y a ceux qui considèrent que l'efficacité n'est pas importante et qui se reposent sur les avancées des matériels informatiques, ce qui peut conduire à des logiciels qui respectent les qualités énoncées précédemment mais qui utilisent ridiculement trop de ressources par rapport à leur fonctionnalité. Il faut noter également que, outre la puissance des ordinateurs, les capacités des techniques de compilation ne font que croître et que certaines optimisations que l'on faisait il y a encore quelques années à la main sont maintenant réalisées automatiquement.
Pour la recherche opérationnelle, l'efficacité est importante et en fonction de l'utilisation à laquelle on destine un composant on favorisera souvent l'efficacité au détriment d'autres critères. Cependant, lorsque l'on cherche à concevoir une bibliothèque de composants, ces critères ont toute leur importance, ne serait-ce que pour fournir des composants fiables, ce qui semble être un prérequis à toute bibliothèque. Mais nous verrons par la suite que l'approche objet permet de bons compromis entre l'efficacité et les autres critères de qualité.
| 6.1.6. Conclusion |
Les critères énoncés précédemment ne sont pas indépendants et très souvent ils s'influencent les uns les autres, en bien ou en mal, et tout l'art de concevoir un logiciel de qualité consiste à trouver un compromis judicieux entre eux. Volontairement la réutilisabilité a été omise de la liste des critères de qualité. Nous n'en n'avons pas encore donné une définition précise, mais le sens commun nous permet déjà de nous rendre compte que tous les critères énoncés précédemment ont un rôle à jouer dans la réutilisabilité. La section suivante se charge d'éclaircir tous ces points.
Nous avons pu voir également que la recherche opérationnelle et en particulier la conception d'une bibliothèque dans ce domaine ne rentre pas dans le cadre habituel du génie logiciel. Certains critères comme la fiabilité et la portabilité sont peut-être plus simples à aborder (quoi qu'il existe un réel problème avec la stabilité numérique qui entraîne un décalage sérieux entre la théorie et la pratique). En revanche d'autres critères comme l'extensibilité et l'efficacité semblent très délicats à combiner.
| 6.2. REUTILISABILITE |
Nous proposons ici d'éclaircir les concepts d'utilisation et de réutilisation, et de définir précisément la notion de réutilisabilité. Nous discutons ensuite de son rôle dans le développement de logiciels de qualité et plus précisément la relation qu'elle établit avec les critères de qualité présentés dans la section précédente.
| 6.2.1. Utilisation ou réutilisation ? |
Avant tout, il faut faire la distinction entre l'utilisation d'un composant logiciel qui consiste à le prendre tel quel et à s'en servir directement pour résoudre un problème, e.g. l'utilisation d'un programme, d'une structure de données ou d'une fonction dans une bibliothèque. La réutilisation est bien une utilisation d'un composant, mais sa fonctionnalité est modifiée, soit en effectuant une modification directe du composant, soit en proposant une extension qui ne modifie pas le composant même. L'utilisation est une finalité, alors que la réutilisation est une préparation d'un composant logiciel à un certain type d'utilisation.
La frontière entre l'utilisation et la réutilisation est mince, cependant beaucoup préconisent une séparation de ces deux concepts (e.g. [Meyer97]) en proposant deux autres critères de qualité: la facilité d'utilisation et la réutilisabilité. La facilité d'utilisation est la capacité d'un composant logiciel à être utilisé simplement. Par utilisation on entend très souvent l'appel du composant dans un programme, mais également la manière de se le procurer, de l'installer et/ou de le compiler dans l'environnement, la clarté de sa documentation...
La réutilisabilité est la capacité d'un composant logiciel à être utilisé pour créer d'autres composants. La réutilisabilité est un concept très subjectif et dépend très fortement des personnes, les réutilisateurs, qui vont effectivement réutiliser le composant. En effet, dans notre problématique, des composants réutilisables pour des spécialistes en recherche opérationnelle ne le seront pas forcément pour des personnes moins expérimentées. Les experts souhaiteront des composants fortement extensibles, pouvant être paramétrés à volonté, alors que les plus novices voudront des composants prêts à l'emploi. Nous allons nous efforcer ici de répondre à ces deux types de réutilisateurs.
Mais avant de continuer, nous voulons apporter des précisions sur ce que nous appelons réutilisabilité dans ce document. La réutilisabilité rassemble tous les facteurs qui favorisent une utilisation ou une réutilisation d'un composant logiciel. Ainsi, la facilité d'utilisation qui est souvent mise à l'écart sera pour nous totalement intégrée au concept de réutilisabilité. Nous pensons qu'un composant trop extensible, même s'il est très réutilisable au sens premier, ne sera pas réutilisable au sens second (cf. section suivante).
Dans notre cas, il ne faut pas non plus oublier que les utilisateurs (ou réutilisateurs) auxquels sont destinés les composants ne sont pas experts en génie logiciel et en programmation orientée objet, qui sera le support de notre bibliothèque comme nous le verrons par la suite. Donc des composants paramétrables avec des concepts objets trop avancés ne seront jamais réutilisés par ces personnes.
| 6.2.2. Réutilisabilité et qualité |
Le but de cette section est d'expliquer les relations qu'il existe entre les différents critères de qualité d'un logiciel et plus particulièrement avec la réutilisabilité. Nous tentons de montrer que la réutilisabilité intervient favorablement dans pratiquement tous les critères, et à l'opposé tous interviennent positivement dans la réutilisabilité.
| 6.2.2.1. Fiabilité |
Tout naturellement la fiabilité d'un composant logiciel va favoriser sa réutilisabilité. En effet, si un utilisateur est convaincu du bon comportement d'un composant, il sera tenté de le réutiliser. A l'opposé, la réutilisabilité peut favoriser la fiabilité, puisque construire un nouveau composant à partir de bases fiables et réutilisables ne peut que faciliter la conception et la vérification du composant. En outre, un composant qui est réutilisé devient fiable au fil du temps car ses défauts ont plus de chance d'être détectés et corrigés par les réutilisateurs.
Cependant, cela forme un cycle dans lequel il est souvent difficile d'entrer. En effet, un composant est réutilisé s'il est fiable et il sera fiable très souvent s'il est réutilisé. On tombe alors sur l'une des difficultés pratiques indépendantes du concepteur d'un composant réutilisable: même si ce dernier est fiable, il faut que des utilisateurs acceptent de prendre un risque à un moment donné. Celui-ci peut se traduire par une réutilisation directe du composant qui peut conduire à de catastrophiques résultats, ou bien alors par un investissement dans des tests sur le composant afin d'évaluer sa fiabilité avant de le réutiliser.
| 6.2.2.2. Extensibilité |
L'extensibilité est un critère indissociable de la réutilisabilité. D'ailleurs dans leur usage quotidien, ces deux concepts sont confondus. Tout composant extensible a forcément un certain degré de réutilisabilité (même si par la suite nous expliquons que trop d'extensibilité peut tuer la réutilisabilité, ce n'est pas l'avis de tous, e.g. [Meyer97], [Kuhl96a]). A l'opposé, des composants réutilisables et donc relativement adaptables vont faciliter la conception de composants à leur tour extensibles.
Par expérience, nous pouvons affirmer qu'un composant logiciel trop difficile à paramétrer n'est pas toujours beaucoup réutilisé. Il faut fournir des composants paramétrables par rapport aux attentes naturelles des réutilisateurs, et ne pas exagérer le nombre de paramètres, afin d'éviter toute confusion.
Java est source d'exemples de ce type. Pour ouvrir un fichier texte en mode lecture avec la
possibilité d'en extraire des mots, des nombres..., il faut créer tout naturellement
un composant représentant le fichier, mais cette opération nécessite la
création de deux composants intermédiaires. Voici la commande en Java qui permet
d'ouvrir le fichier localisé à l'URL (Unified Resource Locator)
u.
f = new StreamTokenizer(new BufferedReader(
new InputStreamReader(u)));
Cependant, avec un minimum d'effort, un composant TextFile pourrait être
conçu pour fournir une syntaxe simple: f = new TextFile(u). La
modélisation par défaut permet certainement beaucoup de flexibilité dans
l'ouverture des fichiers, mais pour des personnes qui veulent ouvrir un simple fichier texte (et
c'est très certainement le cas le plus courant) elle fournit trop de détails
inutiles.
| 6.2.2.3. Homogénéité |
L'homogénéité favorise indéniablement la réutilisabilité, puisqu'une organisation cohérente des composants facilitera leur réutilisation. En effet, après un apprentissage de la logique qui gouverne la structure des composants, il est très facile pour un utilisateur de retrouver les composants dans une bibliothèque et d'en comprendre les différents paramètres (il pourra profiter des similitudes avec d'autres composants qu'il connaît déjà). Il ne faut donc pas dénigrer cet aspect. Nous pensons même que la plupart des bibliothèques, comme les programmes, qui ont du succès ne sont pas celles qui sont les plus fiables, les plus efficaces... mais bien celles dont la prise en main est facile et intuitive. Dans toutes les disciplines, les gens détestent lire une documentation avant d'utiliser un outil.
A l'opposé, la réutilisabilité ne conduit pas forcément à une homogénéité. Ce sont, dans ce sens, des critères relativement indépendants. Mais la réutilisabilité a parfois tendance à rapprocher des composants d'horizons très différents. Un moyen de garantir une homogénéité dans ce cas est de masquer les composants derrière des composants qui eux sont compatibles avec les règles d'écriture et d'organisation. Cependant l'interfaçage fourni par ces composants, appelés adapteurs (cf. [Gamma95]), peut nuire à l'efficacité voire à la réutilisabilité, puisque des extensions très utiles mais incompatibles seront masquées.
| 6.2.2.4. Portabilité |
La portabilité est un facteur qui renforce la réutilisabilité. Un exemple flagrant est Java qui fournit une portabilité de ses composants quasi totale, ce qui explique en grande partie le succès de ce langage. A l'opposé, comme pour la fiabilité, construire un composant à partir de bases portables et réutilisables facilite forcément sa propre portabilité. En revanche, cette propriété nuit généralement beaucoup à l'efficacité, car l'assurer implique d'établir une interface entre l'environnement et les composants. Toute communication entre les deux se fait donc par cette interface, ce qui ralentit forcément l'exécution. Très souvent ce coût est négligeable, mais pour certaines applications critiques, il est très important. L'exemple que l'on connaît le mieux est celui des interfaces graphiques qui perdent significativement de leur efficacité lorsqu'elles sont portables (e.g. Java).
Comme nous l'avons déjà expliqué, ce critère est naturellement amélioré à mesure que les années passent. Avec certains langages, ce n'est même plus un problème puisque leurs spécifications garantissent un standard. Néanmoins pour nous, la portabilité, au même titre que la fiabilité, sont des prérequis à tout composant réutilisable. Nous avons choisi C++ pour développer notre bibliothèque, il s'agit d'un langage dont les spécifications parfois imprécises entraînent de légères ambiguïtés, ce qui rend le problème de la portabilité important (cf. chapitre 8). Néanmoins, dans le domaine de la recherche opérationnelle, la plupart des applications reposent plutôt sur des calculs et très peu d'interactions avec l'environnement sont nécessaires. La seule problématique sérieuse est la représentation des nombres qui peut changer d'une machine (voire d'un compilateur) à une autre.
| 6.2.2.5. Efficacité |
L'efficacité est souvent le critère mis en avant contre la réutilisabilité. Il est souvent supposé que l'utilisation de composants extensibles, autrement dit génériques, par rapport à des composants dédiés est forcément plus lente. Ceci est vrai pour une certaine catégorie de composants réutilisables, en fonction des concepts qu'ils utilisent pour assurer leur extensibilité. Comme nous l'expliquerons au chapitre suivant, la notion d'héritage et le polymorphisme associé sont des concepts très puissants en termes de réutilisabilité, mais leur abus conduit généralement à un code peu performant. A l'opposé, il existe le concept de généricité qui est un compromis idéal entre l'efficacité et la réutilisabilité. A peu de perte de performance, on peut gagner beaucoup en réutilisabilité. Un exemple est la STL (Standard Template Library [SGIWeb], [Stepanov95]) qui fournit des structures de données et les algorithmes associés en C++ qui sont très efficaces et très réutilisables.
Néanmoins, on peut raisonnablement supposer que des composants beaucoup réutilisés sont optimisés. Il y a un réel enjeu à améliorer les performances de tels composants, la répercussion de leur évolution s'étend à de nombreux systèmes logiciels. En outre, lorsque l'on conçoit un programme, il est rare de posséder toutes les compétences requises, cela nécessite généralement des connaissances dans des domaines très variés: algorithmique, structure de données, graphisme, bases de données... Il est donc logique d'avoir recours à des composants logiciels développés par des gens compétents dans le domaine concerné, ayant consacré beaucoup de temps à la conception de ces composants. Il est alors très improbable de produire un composant plus efficace, même s'il est dédié à notre application.
Voici un exemple simple où beaucoup, dont moi, se reconnaîtront. Tout informaticien sait implémenter la structure d'une liste chaînée, et de manière très efficace pense-t-il. En effet, il s'agit d'un outil élémentaire codé par chacun des dizaines de fois. Un ajout se fait en quelques lignes: allocation de la cellule, modification des liens dans la liste. C'est très rapide et efficace. Cependant... A chaque ajout d'un élément dans la liste, une nouvelle cellule est allouée. Cette opération prend beaucoup de temps car le système interroge la mémoire pour savoir où il reste de la place. Une technique célèbre pour améliorer de plusieurs dizaines de pourcents les performances de la liste consiste à allouer une zone mémoire pouvant recueillir un grand nombre de cellules et à gérer soi-même cet espace. Au lieu d'allouer dans la mémoire centrale une cellule, il suffit de piocher dans la zone déjà allouée, et avec une politique efficace, on obtient un gain de performance conséquent. Combien d'informaticiens font cette manipulation chaque fois qu'ils implémentent une liste chaînée ? Peu très certainement. Mais en utilisant par exemple la liste chaînée fournie par la STL, où cet artifice est déjà présent, le développeur gagne à la fois sur son temps de développement et sur l'efficacité de ses composants logiciels.
| 6.2.3. Conclusion |
En conclusion, nous proposons la figure 6.1 qui tente de synthétiser les relations qu'il existe entre les différents critères de qualité. Une case du tableau correspond à l'influence du critère de la ligne sur le critère de la colonne. Une case vide signifie que nous n'avons pas pu décider, soit parce que le critère n'influence pas du tout l'autre, soit parce qu'il est impossible d'en tirer une règle générale.
 |
| Figure 6.1: Relations entre les critères de qualité. |
Ce tableau a été construit à partir des remarques que nous avons énoncées tout au long de ce chapitre. Il est difficile de définir catégoriquement l'influence d'un critère sur un autre, le tableau reflète simplement notre point de vue sur la question. Il faut également noter que nous nous sommes placés dans un contexte assez général et que des cas particuliers peuvent facilement infirmer n'importe quelle case du tableau. Nous remarquerons simplement de ce tableau que tous les critères ont une influence positive sur la réutilisabilité et que l'inverse est souvent vrai, ce qui tente à rapprocher la qualité d'un logiciel de sa réutilisabilité.
| 6.3. NIVEAUX D'ABSTRACTION |
La création d'un logiciel passe par trois grandes phases: l'analyse, la conception et l'implémentation (cf. figure 6.2). Le cycle de développement n'est pas séquentiel et il est courant, voire obligatoire, de revenir sur des étapes antérieures. Ces trois phases représentent différents niveaux d'abstraction. Le premier est très abstrait et consiste en une étude avant même la conception du logiciel. La seconde consiste en l'élaboration de la structure du logiciel, a priori indépendamment de l'environnement informatique sur lequel il sera développé. La dernière phase est la création même du logiciel dans un ou plusieurs langages informatiques. Depuis le début de ce chapitre, nous avons parlé principalement de réutilisabilité au niveau de l'implémentation, mais ce concept existe tout naturellement aux autres niveaux. Nous proposons donc d'en discuter ici, en se posant la question de savoir à quel niveau il est le plus judicieux d'exploiter la réutilisabilité.
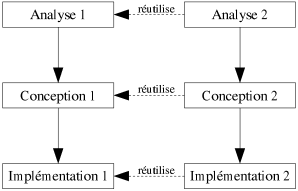 |
| Figure 6.2: Les phases de développement d'un logiciel. |
La figure 6.2 explique comment, en dehors de toute méthode favorisant la réutilisabilité, des logiciels d'un même domaine d'application sont élaborés. D'un premier besoin démarre la création du premier logiciel suivant les trois phases (Analyse 1, Conception 1 et Implémentation 1). Lorsque le besoin d'un nouveau logiciel apparaît, comme aucune stratégie particulière de développement n'a été mise en place, les trois phases sont à nouveau lancées (Analyse 2, Conception 2 et Implémentation 2). Ces dernières réutilisent le peu qu'elles peuvent du premier développement. Mais voyons maintenant comment améliorer la part de réutilisation.
| 6.3.1. Analyse |
L'analyse est l'étape préliminaire à la conception de tout logiciel. Elle consiste principalement à analyser un système et à recenser les besoins des futurs utilisateurs. Le système étudié est celui dans lequel le logiciel doit s'insérer. Par exemple, un logiciel de gestion assistée par ordinateur sera intégré dans les systèmes de production et comptable d'une entreprise; pour une base de données ou un modèle de simulation, le système analysé est celui qu'ils devront représenter. Cette étude est appelée l'analyse de système.
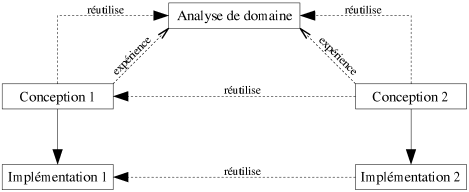 |
| Figure 6.3: Les phases de développement d'un logiciel, avec analyse de domaine. |
Une approche plus abstraite peut être menée, elle consiste à étudier plusieurs systèmes d'un même domaine, dans l'espoir de fournir une analyse commune et de conduire à un environnement logiciel unique. Cette étude est appelée analyse de domaine. Cependant, il est très difficile de concevoir un seul environnement informatique qui réponde aux besoins de tous les systèmes. En revanche, il est possible d'identifier des éléments communs qui permettront de mener des analyses communes (cf. [Leach97], [Cohen98]). Ces résultats pourront alors être réutilisées lors de l'analyse d'un système précis du domaine (cf. figure 6.3). Comme le précise [Campos00], l'analyse de domaine peut s'effectuer progressivement en concevant des logiciels pour plusieurs systèmes d'un même domaine. Un retour d'expérience permet alors d'étoffer l'analyse du domaine.
| 6.3.2. Conception |
La conception est l'étape où la structure du logiciel est élaborée. A ce niveau l'étude est menée indépendamment du ou des langages de programmation qui seront employés pour le logiciel. Cependant, il faut tout de même décider d'une approche de modélisation, e.g. faut-il employer le paradigme objet, un modèle entité-association... A ce niveau tout le logiciel est élaboré, dans un ou plusieurs formalismes.
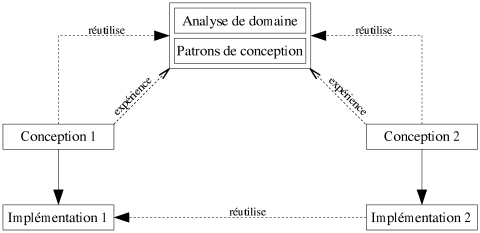 |
| Figure 6.4: Les phases de développement d'un logiciel, avec patrons de conception. |
Lors de ces phases de conception, certains problèmes de modélisation sont récurrents. Des solutions génériques peuvent alors être apportées. Afin d'en permettre une réutilisation, la notion de patron de conception (design pattern) a été introduite (cf. [Schmidt96]). Un patron de conception est un élément réutilisable de conception qui est indépendant du domaine d'application (et bien entendu de tout langage de programmation). Il propose une solution générique à un type précis de problème. Il s'agit donc d'un outil qui permet de mémoriser et de formaliser l'expérience d'experts. Bien qu'il soit indépendant du langage de programmation, un patron de conception n'en est pas moins dépendant de l'approche choisie pour la modélisation. Par exemple, les patrons désormais célèbres fournis dans [Gamma95] proposent des solutions de conception pour l'approche orientée objet. Comme dans la phase d'analyse, un retour d'expérience des différentes conceptions permet d'alimenter les collections de patrons (cf. figure 6.4).
| 6.3.3. Implémentation |
La phase d'implémentation est l'étape qui consiste à programmer proprement dit le logiciel. Notre discussion sur la réutilisabilité a porté principalement sur ce niveau d'abstraction jusqu'à cette dernière section. La figure 6.5 résume l'intérêt d'une bibliothèque de composants dans la phase d'implémentation du logiciel. Comme pour les deux phases précédentes, le retour d'expérience de chaque implémentation permet de fournir la bibliothèque logicielle en nouveaux composants.
Au travers des derniers paragraphes on pourrait penser que plus la réutilisabilité est abstraite, plus sa portée est grande puisqu'elle est indépendante de l'approche et du langage de programmation. Par conséquent, la réutilisabilité logicielle (i.e. au niveau implémentation) n'aurait que peu d'intérêt.
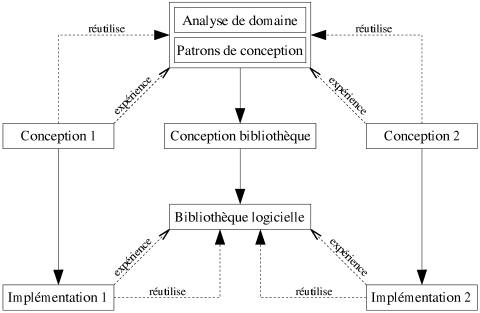 |
| Figure 6.5: Les phases de développement d'un logiciel, avec bibliothèque logicielle. |
Cependant, comme l'explique [Stroustrup96], la réutilisabilité ne peut pas être totalement indépendante du langage de programmation, il y a trop de différences dans les concepts de chacun pour concevoir un bon composant réutilisable à un niveau trop abstrait. A vouloir exprimer quelque chose avec les seules notions communes à plusieurs langages, on en perd une puissance d'expression. L'idéal, c'est de combiner la réutilisabilité aux différentes phases d'élaboration du logiciel, c'est ce que l'on appelle un cadriciel.
| 6.3.4. Cadriciel |
Plusieurs définitions du terme cadriciel (framework) peuvent être énoncées (e.g. [Johnson88], [Mattsson96]). Nous retenons celle de [Campos00] qui s'intègre le mieux à notre discussion: un cadriciel est une collection d'éléments de conception (e.g. les patrons de conception) et d'implémentation (e.g. les composants logiciels) en coopération et réutilisables qui permettent de créer des applications ou des parties d'applications dans un domaine spécifique.
L'idée est de fournir, à partir d'une analyse de domaine, des éléments réutilisables, aussi bien au niveau de la conception que de l'implémentation (cf. figure 6.6). Associés à une assistance informatisée, cela permet à un expert d'un domaine de concevoir un logiciel pour ses besoins sans connaître tous les concepts liés au génie logiciel et en particulier à l'approche orientée objet si elle a été retenue pour la conception. La liste des cadriciels célèbres à l'heure actuelle est longue. Nous n'en citerons que deux types représentatifs: les interfaces graphiques, qui proposent au niveau conceptuel les fenêtres, les boutons... et qui offrent aussi les composants logiciels pour les implémenter; les gestionnaires de bases de données (e.g. Microsoft Access), ils permettent de manipuler à un niveau d'abstraction élevé des bases de données, et fournissent les composants logiciels associés.
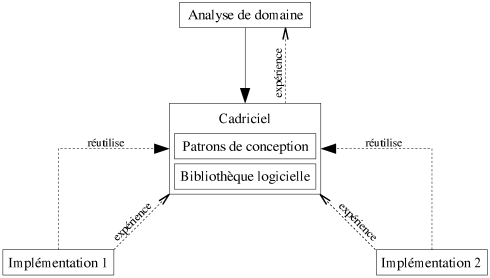 |
| Figure 6.6: Les phases de développement d'un logiciel, avec cadriciel. |
| 6.3.5. Conclusion |
Cette discussion a porté sur l'élaboration de logiciels au sens large. Quand est-il de la recherche opérationnelle et de notre objectif de créer une bibliothèque de composants réutilisables ? En recherche opérationnelle, le processus de développement d'un logiciel est très similaire à celui d'un logiciel au sens classique du génie logiciel. La différence réside dans l'analyse de domaine où les méthodes employées sont radicalement différentes. Pour la recherche opérationnelle, la modélisation des systèmes même est très synthétique, la majeure partie de l'analyse consiste alors à élaborer des méthodes de résolution pour la problématique étudiée. En génie logiciel de manière générale, ou en simulation, la plus importante partie du travail consiste à modéliser les systèmes pour lesquels on aboutit souvent à de larges modèles, comparés à ceux que l'on rencontre en recherche opérationnelle. La résolution des problèmes modélisés est alors plus secondaire et peut concerner d'autres disciplines.
La phase de conception est en revanche très similaire, il s'agit de traduire en termes plus informatiques les résultats de l'analyse de domaine pour établir une structure encore abstraite du logiciel. Cela signifie concevoir logiciellement les structures de données et les algorithmes nécessaires aux méthodes de résolution pour la recherche opérationnelle, et modéliser avec des concepts informatiques les modèles des systèmes pour le génie logiciel ou la simulation. En résumé, la recherche opérationnelle travaille plutôt sur les algorithmes alors que le génie logiciel et la simulation se concentrent sur les données et leurs interactions, même si, en fonction des domaines d'application, les deux approches sont plus ou moins mélangées.
Il est intéressant de noter qu'au niveau de l'analyse de domaine, la recherche opérationnelle est très performante en termes de réutilisabilité. Il existe énormément d'articles qui proposent des méthodes pour résoudre un grand nombre de problèmes. En revanche, en génie logiciel ou en simulation, les articles et les études apportent plutôt des réponses générales sur la manière de modéliser un système, mais semble-t-il un peu moins sur une manière de modéliser les systèmes d'un domaine particulier. A l'inverse au niveau de la conception et de l'implémentation, il est beaucoup plus rare de trouver soit des patrons de conception, soit des composants logiciels pour des problèmes de recherche opérationnelle, alors qu'ils prolifèrent pour le génie logiciel ou même la simulation.
Notre objectif dans ce document sera de présenter quelques patrons de conception et de discuter des problèmes liés à l'implémentation. En aucun cas nous présentons un cadriciel complet pour les problèmes d'optimisation dans les graphes. Néanmoins notre objectif à plus long terme est justement de le fournir et de concevoir l'assistance informatique associée pour disposer d'un environnement de développement d'outils de recherche opérationnelle relativement complet, et suffisamment simple d'utilisation par rapport à tous les concepts de génie logiciel et en particulier l'approche orientée objet (présentée au chapitre suivant).
| 6.4. L'EVOLUTION VERS LES OBJETS |
Avec des ordinateurs de plus en plus puissants, l'homme cherche toujours à concevoir des logiciels, modéliser, simuler et résoudre des systèmes de plus en plus complexes. Cependant, sa capacité à appréhender cette complexité est très limitée. Pour tenter de la maîtriser, l'homme a progressivement développé des concepts. Nous allons rappeler ici leur évolution, qui a conduit à la notion d'objet (le fil conducteur de cette présentation est extrait de [Hill96] et [Satzinger96]).
| 6.4.1. Sous-programmes |
Les premiers langages assembleurs ne fournissaient aucun concept particulier pour concevoir un programme structuré, qui se résumait alors en une simple séquence d'instructions. Même avec relativement peu de lignes, de tels programmes sont très difficiles à maintenir. En outre, une même séquence d'instructions peut être répliquée plusieurs fois dans un même programme. C'est donc tout naturellement que les premiers langages structurés (e.g. COBOL, Fortran) sont apparus, proposant la notion de sous-programme. Cette entité regroupe une séquence d'instructions pour former une opération plus sophistiquée. Un sous-programme peut être paramétré, notamment sur les données qu'il traite, afin de remplacer des séquences d'instructions similaires.
Un sous-programme est finalement écrit une seule fois dans un programme, même s'il est utilisé plusieurs fois. Il permet également à un programmeur de réutiliser simplement des parties d'un programme d'un autre développeur. Ce sont les premiers pas vers la réutilisabilité. Un autre apport des sous-programmes est de cacher de l'information. En effet, il n'est pas nécessaire de connaître tous les détails du fonctionnement interne d'un sous-programme pour l'utiliser. Cet aspect est important, puisqu'à un certain niveau du développement d'un logiciel, il est possible de le considérer comme un assemblage de sous-programmes et de se concentrer uniquement sur leur organisation, sans être troublé par des détails inutiles à ce moment de l'étude.
| 6.4.2. Modules |
Cependant, le masquage des informations n'est que partiel. Les sous-programmes ne sont pas des entités totalement indépendantes, certains nécessitent de faire appel à d'autres pour réaliser leur propre fonctionnalité. En revanche, tous n'ont pas besoin d'avoir accès à tous les sous-programmes. De la même manière, plusieurs sous-programmes peuvent partager des données, mais il serait souhaitable que n'importe quel sous-programme ne puisse pas y accéder. Afin de permettre la définition d'une zone où des données et des sous-programmes ne sont visibles qu'entre eux, le concept de module a été introduit. La logique veut qu'un module regroupe des données et des sous-programmes qui participent à une même fonctionnalité. Mais n'oublions pas que certains composants d'un module doivent être visibles par d'autres, tout simplement pour qu'il puisse faire profiter de ses fonctionnalités. Les composants d'un module sont donc séparés en deux ensembles: l'un est visible par tout le programme (l'interface), l'autre est complètement caché (l'implémentation).
Ce concept de module permet d'accroître l'abstraction que l'on peut faire d'un logiciel: il peut être vu comme un ensemble de modules en interaction. Cela permet notamment une étude partielle séparée de chaque module. En outre, les données se trouvant dans l'implémentation d'un module sont isolées et modifiées seulement par un nombre restreint de sous-programmes, ce qui permet d'en garantir une certaine fiabilité.
| 6.4.3. Types abstraits de donnée |
La notion de module est intéressante, mais les données partagées par les sous-programmes d'un module sont uniques dans le programme. Imaginons un exemple simple qui consiste à concevoir un module pour gérer les éléments d'une pile. Supposons que la structure de données de la pile (par exemple un tableau) se trouve dans le module, et soit par conséquent unique dans le programme (cf. figure 6.7). Les sous-programmes du module sont dans l'interface et permettent de l'extérieur d'ajouter, de retirer, accéder... aux éléments de la pile. Mais comment obtenir différentes piles dans un même programme ? Il faudrait dupliquer autant de fois que nécessaire les données du module. Pour répondre à ce besoin, la notion de type abstrait de donnée a été introduite (e.g. le langage Ada).
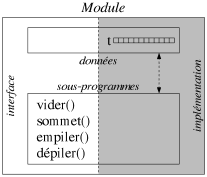 |
| Figure 6.7: Un exemple de module. |
Un type abstrait de donnée est un modèle qui permet de créer à volonté des entités semblables aux modules. Ces entités ont une interface et une implémentation, les données et les sous-programmes qu'elles abritent ont la même visibilité que dans un module, et donc seuls les sous-programmes d'une entité peuvent modifier ses données cachées. La seule différence, comme la figure 6.8 le montre, est que les sous-programmes font partie du type abstrait de donnée, ils sont donc uniques dans le programme alors que les données sont localisées dans chaque entité.
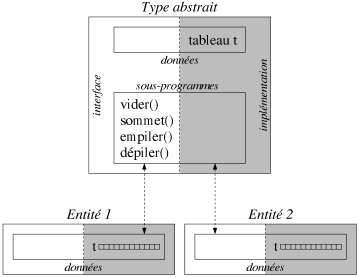 |
| Figure 6.8: Un exemple de type abstrait de donnée. |
La figure 6.8 reprend notre exemple de pile: un type abstrait de donnée décrit la pile qui peut ensuite être physiquement créée en autant d'exemplaires que l'on souhaite (sur la figure Entité 1 et Entité 2). En résumé, un type abstrait de donnée est un type qui représente une structure de données pour laquelle un certain nombre d'opérations (les sous-programmes) sont définies (et ce sont les seules autorisées à manipuler la structure de données). Après une première évolution de langage qui a permis de réutiliser du code (i.e. les sous-programmes) et de le cloisonner (i.e. le module), le type abstrait de donnée propose une réutilisation des structures de données.
| 6.4.4. Objets |
La notion d'objet a été introduite dans le milieu des années 60 avec le langage SIMULA, dédié à la simulation à événements discrets. Il apporte un ensemble de nouveaux concepts que l'on regroupe de nos jours sous le terme d'approche orientée objet, ou de paradigme objet. Sa principale contribution est le renforcement du concept de type abstrait de donnée par la notion de classe. Les entités créées sur le modèle d'une classe sont appelées des objets. En plus d'unifier des opérations et des données dans une même entité, les classes peuvent être organisées en hiérarchie par un mécanisme appelé héritage. Ce concept est très important pour la réutilisabilité, puisqu'il permet à une classe héritant d'une autre de s'approprier toutes les données et les opérations de cette dernière, afin de les adapter à ses propres besoins. La réutilisabilité est également renforcée par le concept de polymorphisme associé à l'héritage. Tous ces termes sont bien entendu introduits en détail au chapitre suivant.
D'autres langages suivirent... Dans les années 70, Smalltalk introduit le terme d'objet dans le contexte du génie logiciel et formalise leur interaction avec la notion de message, qui est une requête d'un objet à un autre lui demandant d'exécuter l'une de ses méthodes. Les années 80 ont vu l'évolution de langages existants vers l'approche orientée objet, e.g. C vers C++, les versions orientées objet de Pascal... A la fin de cette décennie, et au tout début des années 90, les premiers cadriciels pour les interfaces graphiques apparaissent, ce qui donne naissance très rapidement au langage Java dont les fonctionnalités multimédia font le succès. Il s'agit actuellement du plus jeune des langages généralistes orientés objet dont l'utilisation est très répandue.
| 6.4.5. Conclusion |
Nous pouvons alors constater que l'évolution des langages de programmation a été guidée par un souci de maîtrise de la complexité des systèmes modélisés et par un besoin de réutilisabilité. Mais ces deux facteurs n'ont-ils pas finalement des objectifs communs ?
La complexité des logiciels ou des systèmes que l'on cherche à modéliser est généralement trop importante pour être appréhender clairement par l'esprit humain. En outre, ce travail est réalisé par une équipe composée de personnes de différents domaines: des analystes, des programmeurs, des experts du domaine à étudier... La nécessité de communiquer entre eux ne fait qu'accroître la difficulté d'appréhender le problème dans son ensemble. Afin de maîtriser cette complexité, des concepts ont dû être développés: l'abstraction, l'encapsulation, la modularité et la hiérarchie (cf. [Booch91], [Hill96]). Ces notions sont omniprésentes dans l'approche orientée objet.
Nous avons discuté de ces concepts sans les nommer lors de la présentation de l'évolution des langages. L'abstraction est le fait de voir toute une partie d'un système comme une entité ayant un rôle défini (e.g. un sous-programme, un module, un type abstrait de donnée, une classe). L'encapsulation est le fait de cacher des informations à l'utilisateur ou au réutilisateur. Ce concept renforce la notion d'abstraction, puisqu'il permet de choisir les éléments visibles de l'extérieur, qui reflètent normalement le rôle du composant. La modularité est le fait de décomposer un système en sous-ensembles, regroupant les composants par fonctionnalité. [Booch91] préconise de rendre les modules aussi indépendants que possible les uns des autres, alors que les composants d'un module sont fortement liés entre eux par un partage de données ou de fonctionnalités.
La hiérarchie est le fait d'organiser les composants d'un système. Lorsque le nombre de composants devient trop important, il est nécessaire, à la fois pour la compréhension du système et pour une clarté indispensable au développement d'un logiciel de qualité, de structurer les composants. [Booch91] propose deux types de classification. La première est caractérisée "appartient à" (elle correspond aux notions d'agrégation et de composition dans l'approche orientée objet). Une entité peut être considérée comme appartenant à une entité plus grande. La seconde classification est caractérisée "est un" (elle correspond à l'héritage dans l'approche orientée objet). Elle consiste à classer les composants dans des catégories hiérarchisées de la plus générale à la plus spécifique.
Ces concepts sont bien évidemment favorables à la réutilisabilité. L'abstraction et l'encapsulation correspondent parfaitement à l'utilisation simple d'un composant: il a un rôle, mais son fonctionnement interne est inconnu. La modularité et la hiérarchie permettent d'organiser les composants, ce qui facilite la compréhension du réutilisateur. En outre, les deux types de hiérarchie exposés au paragraphe précédent autorisent respectivement l'assemblage de composants pour en former un plus grand, et la création d'une sous-catégorie afin d'adapter les fonctionnalités d'une catégorie. Tout cela favorise l'extensibilité des composants.
| CONCLUSION |
En résumé, la réutilisabilité n'entraîne pas d'approche radicalement différente dans le développement de logiciels. Au contrainte, tenter de concevoir des composants réutilisables favorise à long terme le développement de logiciels de qualité. Néanmoins, nous nous sommes concentrés dans ce chapitre sur les aspects techniques et parfois psychologiques liés à la réutilisabilité, mais en très peu d'occasions nous avons parlé des aspects économiques et organisationnels, liés plus directement à la notion de productivité (cf. [Coulange98]). Nous proposons ici une rapide discussion autour de ces aspects, afin d'en entrevoir certaines difficultés.
Certains ouvrages (e.g. [Stroustrup95], [daSilva96]) précisent que le temps consacré à la réutilisation d'un composant inclut le temps de le récupérer (i.e. rechercher le composant le mieux adapté), de l'évaluer (i.e. le composant est-il fiable ?), de le modifier (i.e. l'étendre aux nouveaux besoins) et de l'intégrer (i.e. l'insérer dans l'environnement logiciel où il est réutilisé). Cela soulève d'importants problèmes.
Tout d'abord, comment trouver un composant adapté ? [Leach97] préconise qu'une équipe soit chargée de l'aspect réutilisabilité et réutilisation, à la fois pour examiner les composants disponibles sur le marché, mais aussi pour en produire et fournir un catalogue référençant tous ces composants, afin de permettre une consultation facile et efficace de la part des réutilisateurs.
Il faut également se préoccuper de la sûreté de ces composants. De manière intentionnelle ou non, un mauvais fonctionnement d'un composant peut entraîner un fonctionnement désastreux de tout un système. Pour sécuriser la réutilisation d'un composant, [Waldo98] explique que les systèmes distribués, où les composants sont sur différentes machines et communiquent par un langage indépendant, empêchent que l'échec d'un seul composant ne se répercute sur tout le système. Ce dernier reste alors opérationnel avec seulement quelques fonctionnalités manquantes liées au composant défectueux. En ce qui concerne des malfonctions intentionnelles (comme un virus embarqué dans un composant), le langage Java propose par exemple que le fournisseur encrypte ses composants en fournissant une clé publique permettant à tout le monde de vérifier qu'un composant est intègre, c'est-à-dire qu'aucune modification n'a été apportée au composant sans l'autorisation du fournisseur (e.g. [Niemeyer97]).
Pour en revenir plus directement à la productivité, il faut noter que la réutilisabilité est un investissement à long terme, il ne faut pas espérer en tirer des bénéfices dès l'écriture des premiers composants. En effet, le temps nécessaire à la conception de composants réutilisables est bien supérieur à la création de n'importe quel composant dédié. Le bénéfice s'effectue au moment de la réutilisation du composant. Les profits de la réutilisabilité n'apparaîtront qu'après le développement de plusieurs logiciels.
En outre, des aspects plus stratégiques peuvent freiner la réutilisabilité. En effet, si une entreprise fournit à d'autres ses composants, elle ne sera peut être plus sollicitée pour créer d'autres logiciels pour cette même société (et l'on peut penser que ce sera d'autant plus vrai que ses composants seront de bonne qualité). Créer un logiciel dédié est plus intéressant pour le producteur: tout changement dans les besoins du client passera forcément par une demande de modification, en premier lieu au fournisseur du produit original. Les producteurs de logiciels n'ont donc qu'un intérêt limité dans la diffusion de composants réutilisables. En revanche, pour leur fonctionnement interne, la réutilisabilité est très intéressante, puisqu'elle permet un développement rapide de logiciels, qu'ils soient dédiés à la vente ou à un service de l'entreprise.
Ce chapitre nous a également permis de préciser les particularités de la recherche opérationnelle dans le développement de composants logiciels, par rapport à l'approche classique du génie logiciel. En effet, alors que la recherche opérationnelle se concentre principalement sur l'algorithmique, le génie logiciel se concentre plutôt sur la modélisation de systèmes. Nous avons également formalisé en termes de génie logiciel notre objectif de fournir un cadriciel pour le développement d'outils de recherche opérationnelle. Comme nous l'avons déjà précisé, nous ne proposons ici qu'une simple contribution à ce cadriciel qui s'inscrit dans une vision à plus long terme. Néanmoins, nous tenterons, au travers d'un constat sur notre propre expérience, d'apporter des éléments de réponse sur la manière de développer des composants logiciels réutilisables pour la recherche opérationnelle. Enfin, suite à notre discussion sur l'évolution des langages de programmation, l'orientation objet semble être l'approche la plus avancée et mûre actuellement pour élaborer des composants réutilisables et efficaces. Elle guidera donc la suite de notre étude.
Il faut tout de même noter que l'approche orientée objet n'est pas l'ultime progrès dans la conception de logiciels. L'expansion d'Internet avec son architecture distribuée tend à considérer, grâce aux concepts de la programmation orientée objet et aux technologies client / serveur, la conception de logiciels sous une forme séparable plutôt que monolithique (cf. [Brown96]). Cette vision d'un programme comme un assemblage de composants a donné naissance à l'approche basée composant. Elle insiste sur une utilisation de composants standards et sur le développement de composants suffisamment complets pour tendre vers une utilisation exclusivement boîte noire (i.e. sans connaître les détails) des composants (cf. [Jazayeri95]). Cette approche est souvent comparée à la manière actuelle de concevoir des circuits électroniques, et hérite des mêmes problèmes liés aux relations client / fournisseur (cf. [Clements96]), notamment concernant la normalisation des composants et leur catalogage systématique. Il est intéressant de constater que cette approche basée composant est très bien implantée dans le domaine de la simulation à événements discrets (e.g. DEVS, HLA, VSE, Silk [Pidd99]), qui est à l'origine de l'approche orientée objet avec SIMULA, et qu'elle est également pionnière dans l'utilisation de composants distribués sur Internet (cf. [Pidd99], [Campos00]).
|